
Utiliser des librairies : OpenCV
En Python, on déclare les librairies avant utilisation
Officiellement, il y a deux versions de OpenCV : cv and cv2.
cv : La version initiale, fort utilisée avec le C++, et qui implémente des le format « cvMat », une approche matricelle des données.
Cette version était réputée lente…
cv2 : La version actuelle, et totalement basée sur Numpy.
On utilise de objets NumPy (comme les « ndarray ») et les objects natifs de Python ( lists,tuples,dictionary, etc). Mais NumPy est reconnu pour être très rapide dans les calculs matriciels. .
Exemple : une « ndarray » array[i,j] permettra d’accéder au pixel à (i,j)
Exemple : additionner deux images : res = img1+img2.
Conclusion : CV2 est plus rapide, efficace et intégrée. Mais comme on ré-utilise souvent ses codes, au fur et à mesure du temps,
faire :
import cv2 as cv
Va permettre d’utiliser « cv » pour adresses les fonctions (sans modifier son ancien code) et de se préparer à cv3 !
Remarque : dans OpenCV, on trouvera des fonctions
OpenCV’s application areas include:
- 2D and 3D feature toolkits
- Egomotion estimation
- Facial recognition system
- Gesture recognition
- Human–computer interaction (HCI)
- Mobile robotics
- Motion understanding
- Object identification
- Segmentation and recognition
- Stereopsis stereo vision: depth perception from 2 cameras
- Structure from motion (SFM)
- Motion tracking
- Augmented reality
Et pour supporter toutes ces fonctionnalités, OpenCV inclus une « statistical machine learning library » qui contient :
- Boosting
- Decision tree learning
- Gradient boosting trees
- Expectation-maximization algorithm
- k-nearest neighbor algorithm
- Naive Bayes classifier
- Artificial neural networks
- Random forest
- Support vector machine (SVM)
- Deep neural networks (DNN)
Conclusion : il y a peu de limites à de nombreux projets d’astronomie… Depuis toutes les phases de traitement aux phases de reconnaissances automatiques…
Comment lire une image TIFF 16/32bits ?
Comme expliqué précédemment, j’ai choisi d’utiliser la librairie OpenCV pour cette tâche. La première cible est de lire une image de type « haute résolution » en TIFF avec 16 ou 32 bits de précision.
Voici le code :
Read a DSS stacked image in 16 or 32 bits value
import cv2 as cv
import numpy as np
import matplotlib.pyplot as plt
#Read DSS stacked image in float(16/32) bits value
#>>> in this case, the Lion's Triplet galaxy group
image = cv.imread('F:\TripletLion\Autosave.tif', -1)
print("Image type : ",image.dtype)
print("Image size :",image.shape)
#CV2 convert original values to float value (range [0..1], 1 = original 65535)
print("Image values range : from ",image.min()," to ",image.max())
print("Image mean value : ",image.mean())Exécution:
Image type : float32
Image size : (3353, 5164, 3)
Image values range : from 6.833779e-06 to 0.99609375
Image mean value : 0.018040543
Commentaires :
Comme exemple, j’ai volontairement pris ici une mauvaise image TIFF…
Celle qui est issue par DSS (en interne) en fin d’empilement et qui n’est pas celle qu’il faut utiliser pour la traiter ensuite… Mais que nombre d’amateurs s’obstinent cependant à utiliser 🙁 (Alors qu’il suffit de sauver l’image via la fonction prévue pour tout solutionner).
Mais donc, bonne nouvelle, cela fonctionne ici !
Selon que l’on est en C++ ou Python, le comportement de imread() change.
- plus de flags « standards » (issus du header de C)
- plus de constructeur de type « matrice » utilisé couramment en C, qui est remplacé par Numpy. Les valeurs lues sont donc désormais fournies dans l’espace 0..1 (que ce soit pour 16 ou 32 bits)
- Si l’image à lire est en 16 ou 32 bits, il faut explicitement coder le flag « -1 »
- L’ordre des plans « couleur » fournis en OpenCV est BGR (et pas RGB)
Lire une image PNG ou JPEG
imread() supporte nativement les formats BMP, JPEG, JPEG2000, PNG, PBM, PGM, PPM, SR (Sun raster), RAS (raster), TIFF.
Il est documenté avec des « flags » de lecture supplémentaires :
- -1 : lecture de l’image avec le niveau maximum d’informations (niveaux et canaux) :
- 0 : lecture d’une image et conversion vers niveaux de gris
- 1 : lecture en 8 bits et 3 canaux couleurs : BGR
#Read a 8bits image
import cv2 as cv
import numpy as np
import matplotlib.pyplot as plt
#Read a image in at maximum info (if > 8bits)
image = cv.imread('F:\TripletLion\Image_orig_withlevel.PNG', -1)
print("Image type : ",image.dtype)
print("Image size :",image.shape)
plt.title("imread -1")
imgplot = plt.imshow(image)
plt.show()
#Read a image and convert to grayscale
image = cv.imread('F:\TripletLion\Image_orig_withlevel.PNG', 0)
print("Image type : ",image.dtype)
print("Image size :",image.shape)
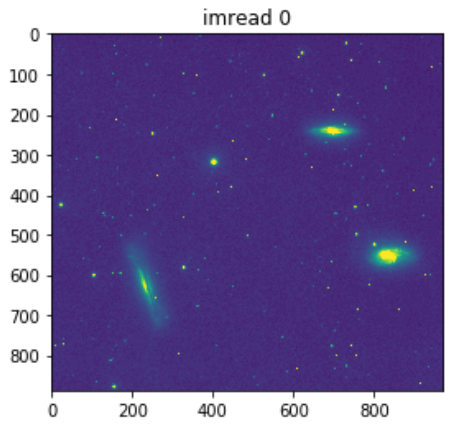
plt.title("imread 0")
imgplot = plt.imshow(image)
plt.show()
#Read a image by default (no flag)
image = cv.imread('F:\TripletLion\Image_orig_withlevel.PNG')
print("Image type : ",image.dtype)
print("Image size :",image.shape)
plt.title("imread")
imgplot = plt.imshow(image)
plt.show()
#Read a image in standard color mode
image = cv.imread('F:\TripletLion\Image_orig_withlevel.PNG', 1)
print("Image type : ",image.dtype)
print("Image size :",image.shape)
plt.title("imread 1")
imgplot = plt.imshow(image)
plt.show()A l’éxécution:
Image type : uint8
Image size : (887, 972, 4)
Image type : uint8
Image size : (887, 972)
Image type : uint8
Image size : (887, 972, 3)
Image type : uint8
Image size : (887, 972, 3)


Commentaires :
En soi, le traitement gagne à l’utilisation systématique du flag « -1 » pour lire et stocker l’image originale. Quand au flag « 1 » (ou par défaut), il fournit une image « standard ».
Le flag de conversion vers niveaux de gris (0) devrait exploiter les mécanismes de conversion par défaut de OpenCV. L’aspect « couleur » montré ici est un effet « spectre par défaut » de la fonction d’affichage (imgplot()).
Si on compare avec une conversion exécutée autrement (type Photoshop), on peut voir la différence :

Ouverture d’une image sans connaître son niveau de précision (8,16,32,48)
Si on tente l’ouverture d’une image 32 bits avec un imread() avec un flag « any depth »
image = cv.imread('F:\TripletLion\Autosave.tif'', -1)
Cela fournira correctement une image de type
Image type : float32
Image size : (3353, 5164, 3)
Par contre, si on tente l’ouverture de la même image (32 bits) avec un imread() sans option particulière, il s’exécutera correctement…
Mais le contenu lu sera vide !
Et toute tentative d’usage de la variable « image » finira avec un
AttributeError: 'NoneType' object has no attribute 'dtype'
La solution à ce problème est simple :
image = cv.imread('F:\TripletLion\Autosave.tif')
if image is None:
image = cv.imread('F:\TripletLion\Autosave.tif',-1)
Qui fournira toujours une variable sur laquelle on pourra tester au moins le type et en déduire le traitement à appliquer par ensuite (si dtype = float32, on sait quoi faire…).
Conversion de format « rapide »
Dans l’interface Python <> C de OpenCV, certaines des fonctions de conversion de format liées « matrice » disparaissent. On va donc se baser sur Numpy.
Pour stocker les images, on peut définir
#Define storage types
image_int8 = np.zeros((row,cols,depth),dtype="uint8")
image_int16 = np.zeros((row,cols,depth),dtype="uint16")
image_float16 = np.zeros((row,cols,depth),dtype="float16")
image_float32 = np.zeros((row,cols,depth),dtype="float32")Puis utiliser ces variables pour stocker/convertir les images lues
#Convert to float 16 bits (0..1)
image_float16 = image_float32.astype("float16")
#Convert to int 16 bits (0..65536)
image_int16 = (image_float32 * 65536).astype("uint16")
#Convert to int 8 bits (0..255)
image_int8 = (image_float32 * 255).astype("uint8") Sauver les images (tout format standard)
imread() possède des options, son équivalent imwrite() en possède d’autres.
On utilise parfois aussi les « universal FileStorage I/O functions » pour sauver les images (on y reviendra avec le format RAW).
Au niveau imwrite(), pour choisir un format cible : il suffit de mettre la bonne extension dans le nom de fichier. Voyons un code qui « fait » tout…
Et pour faire bonne mesure, on rajoute quelques fonctions orientées « file system ».
#Python program to explain cv2.imwrite() method
importing cv2 as cv
importing os module
import os
#Image path
image_path = r'C:\Users\image01.png'
#Image directory
directory = r'C:\Users\Photolib'
#Using cv2.imread() method to read the image
img = cv2.imread(image_path)
#Change the current directory to specified directory
os.chdir(directory)
filename = 'savedImage.jpg'
cv2.imwrite(filename, img)
print('Successfully saved')Options / restrictions de imwrite()
JPEG : la qualité de 0 à 100 (la plus haute), 95 est la valeur par défaut.
PNG : la compression de 0 à 9 (la plus haute), 3 est la valeur par défaut.
PPM, PGM, or PBM : autrefois célèbre sur PC (temps du MS-DOS), peuvent être binaire (1) ou pas (0), binaire par défaut.
PNG, JPEG2000, TIFF : soit unsigned 8 ou 16 bits, selon la documentation
Alpha channel
Ce format alliant une 4ème couche dans l’image (pour les masques, luminosité ou autre usage) est fréquent en astrophoto.
PNG, TIFF : le supporte, selon la documentation,
- en unsigned 8 et 16 bits
- en ordre BGRA des couches
- le pixel « transparent » vaut 0 (= pas d’action)
- le pixel « opaque » (= masque) vaut la valeur maximale (soit 255 ou 65536)
Rappel : en Photoshop, par exemple, si un pixel de masque est « blanc » (RGB 255,255,255) : il est « transparent » (donc laisse passer les informations du calque inférieur) . Si le pixel de masque est « noir » (RGB 0,0,0), il « cache » le calque inférieur. Donc : c’est l’inverse ici !
image = cv.imread('F:\TripletLion\Autosave.tif')
if image is None:
image = cv.imread('F:\TripletLion\Autosave.tif',-1)
#Convert to Grayscale : Weighted or Luminosity method
# ((0.3*R) + (0.59*G) + (0.11*B))
grayscale_float32 = (image[:,:,2]*0.3 + image[:,:,1]*0.59 + image[:,:,0]*0.11)
fn = "F:\\TripletLion\\" + "grayweighted_float32bits" + ".tif"
cv.imwrite(fn, grayscale_float32)Lit l’image, la convertit en niveau de gris (voir la page dédiée pour plus d’information) et la sauve de nouveau sous Tiff, qui sera une image TIFF mono level et normalement en 16bits.
Lire une image FITS
Il faut utiliser la librairie pyfits de astropy.io . Avec l’environnement Anaconda, la librairie astropy est normalement livrée dès le départ.
import astropy
astropy.test()
Va exécuter un (long) script de test qui va valider toutes les fonctions disponibles (dont celles liées à fits, dans le sous-groupe io)
Si cela ne fonctionne pas, il faut faire un « conda update astropy » (ce qui prend du temps avec toutes les dépendances).
La librairie comporte une série de fonctions : open(), writeto(), info(), printdiff(), append(), update(), getdata(), getheader()
getval(), setval(), delval() qui seront utiles plus tard.
Mais tout d’abord :
from astropy.io import fits fits_image_filename = "F:\\TripletLion\\Autosave.fits" hdulist = fits.open(fits_image_filename)
Réalise la lecture de l’image indiquée, très simple… Mais une image FITS ne se lit pas directement car elle comporte plusieurs parties logiques et open() renvoie une liste d’objets qu’il faudra traiter séparément.
Autre commentaire : remarquez les « \\ » dans le nom du fichier de sauvegarde… Cela peut être très utile, sous Windows…
Revenons aux objets de Fits, avec deux exemples d’images
fits_image_filename = "F:\\Autosave.fits" hdulist = fits.open(fits_image_filename) print(hdulist.info()) fits_image_filename = "F:\\TripletLion\\WFPC2.fits" hdulist = fits.open(fits_image_filename) print(hdulist.info())
A l’éxécution, fournit :
Filename: F:\TripletLion\Autosave.fits No. Name Ver Type Cards Dimensions Format 0 PRIMARY 1 PrimaryHDU 20 (5164, 3353, 3) uint8 None Filename: F:\TripletLion\WFPC2.fits No. Name Ver Type Cards Dimensions Format 0 PRIMARY 1 PrimaryHDU 262 (200, 200, 4) float32 1 u5780205r_cvt.c0h.tab 1 TableHDU 353 4R x 49C [D25.17, D25.17, E15.7, E15.7, E15.7, E15.7, E15.7, E15.7, E15.7, E15.7, A1, E15.7, I12, I12, D25.17, D25.17, A8, A8, I12, E15.7, E15.7, E15.7, E15.7, E15.7, E15.7, I12, I12, I12, I12, I12, I12, I12, I12, A48, E15.7, E15.7, E15.7, E15.7, E15.7, E15.7, E15.7, E15.7, E15.7, E15.7, E15.7, E15.7, E15.7, E15.7, E15.7] None
Petit décodage : les composants d’une FITS peuvent être variés…
Dans le premier cas : on retrouve une simple image en uint 8 bits.
Dans le deuxième : une image en float 32 bits avec une table de valeurs « HDU »…
La discussion des « header » data sera abordé lors de l’analyse d’une image et des traitements appropriés…
Pour le moment, pour accéder au contenu « image », il suffit de faire appel à l’objet de type « PrimaryHDU » et qui porte un « nom » spécifique, « PRIMARY » dans le cas présent.
Remarquons qu’une image FITS peut contenir plusieurs « images », même d’autres choses… La norme, prévue pour le stockage et le transport et l’archivage des données scientifiques permet d’y stocker de nombreux types d’information:
- Matrices multi-dimentionnelles : 1D spectre, 2D images, 3D+ data cubes
- Tables contenant des lignes et colonnes d’information
- Avec un « Header » qui décrira le contenu
Faisons un tour rapide des possibilités (issu de la documentation du standard : https://fits.gsfc.nasa.gov/fits_documentation.html
« A FITS file is comprised of segments called Header/Data Units (HDUs) which may be any of four formats. The table indicates the formats each package supports.
- FITS images are generally supported and can include 1-999 dimensional arrays of unsigned bytes, signed 2 and 4 byte integers and 4 and 8 byte floating point numbers using IEEE representations. Some packages may only read images in the first HDU.
- FITS binary tables store tabular information in a binary representation. Each cell in the table can be an array but the dimensionality of the array must be constant within a column. Binary tables can support the datatypes available for images as well as logical variables (stored as T and F), bit arrays, characters, strings (stored as arrays of characters), and 8 and 16 byte complex numbers.
- FITS ASCII tables store tabular information with all numeric information stored in ASCII formats. While ASCII tables are generally less efficient than binary tables, they can be made relatively human readable and can store numeric information with essentially arbitrary size and accuracy (e.g., 16 byte reals).
- The random groups extension is deprecated but is nonetheless extensively used in radio astronomy. It allows groups of arrays where each element of the group has exactly the same dimensionality.
Variable-length-arrays are widely used. There one or more columns in a FITS binary table consists of pointers to a heap area with each pointer defining the length and location of the array entry for the given row.
Many FITS readers can read information that has been stored using standard compression algorithms, particularly the .Z and .gz files created by the Unix compress and gzip utilities. FITS also supports compression internally for both images and binary tables which can be more efficient for astronomical data and can also allows access to uncompressed image metadata.
Several additional conventions are also supported by some FITS readers. Some of these are part of the official standard but may not be supported by all readers. Users may wish to ensure that their specific communities’ software are prepared to handle these features before committing to them.
- The long-string convention allows FITS headers to specify string values longer than 68 characters.
- The FITS hierarchical grouping convention defines a kind of FITS table which describes an association of HDUs which may span multiple files.
- The header inheritance convention allows for FITS header information in the primary HDU to be used to default information in subsequent HDUs.
- The HIERARCH keyword convention allows FITS keywords to be longer than the standard value of 8 characters. »
En pratique :
fits_image_filename = "F:\\TripletLion\\Autosave.fits"
hdulist_1 = fits.open(fits_image_filename)
print(hdulist_1.info())
fits_image_filename = "F:\\TripletLion\\WFPC2.fits"
hdulist_2 = fits.open(fits_image_filename)
print(hdulist_2.info())
#to access image via position into value list
image = hdulist_1[0].data
print("Image type : ",image.dtype)
print("Image size :",image.shape)
image = hdulist_2[0].data
print("Image type : ",image.dtype)
print("Image size :",image.shape)
#to access image via its name into header list
image = hdulist_2['PRIMARY'].data
print("Image type : ",image.dtype)
print("Image size :",image.shape)Ce qui donne :
Filename: F:\TripletLion\Autosave.fits
No. Name Ver Type Cards Dimensions Format
0 PRIMARY 1 PrimaryHDU 20 (5164, 3353, 3) uint8
None
Filename: F:\TripletLion\WFPC2.fits
No. Name Ver Type Cards Dimensions Format
0 PRIMARY 1 PrimaryHDU 262 (200, 200, 4) float32
1 u5780205r_cvt.c0h.tab 1 TableHDU 353 4R x 49C [D25.17, D25.17, E15.7, E15.7, E15.7, E15.7, E15.7, E15.7, E15.7, E15.7, A1, E15.7, I12, I12, D25.17, D25.17, A8, A8, I12, E15.7, E15.7, E15.7, E15.7, E15.7, E15.7, I12, I12, I12, I12, I12, I12, I12, I12, A48, E15.7, E15.7, E15.7, E15.7, E15.7, E15.7, E15.7, E15.7, E15.7, E15.7, E15.7, E15.7, E15.7, E15.7, E15.7]
None
Image type : uint8
Image size : (3, 3353, 5164)
Image type : >f4
Image size : (4, 200, 200)
Image type : >f4
Image size : (4, 200, 200)
Comme on le voit, le résultat des deux dernières méthodes est identique et fournit de nouveau une « array » Numpy utilisable.
Mais attention ici : ordre différent de celui de imread ! 🙁
Car
cv.imread() => height, width, levels
Fits.open => levels, height, width
Et
cv.imread() => BGR
Fits.open => RGB ou autre chose…
Donc : inverser plans et valeurs avant d’utiliser l’un ou l’autre format via les fonctions Numpy (ex : en travaillant canal par canal, puis en recombinant ensuite).
Lire une image RAW
Il faut utiliser la librairie rawpy, qui va proposer d’accéder
- au « header » technique de l’image
- au « miniature » (format JPEG, généralement)
- Au données « RAW » elle-même.
Et pour changer, on va utiliser une autre librairie et examiner les effets.
import rawpy
import imageio
path = 'F:\TripletLion\DSC1407.ARW'
with rawpy.imread(path) as raw:
rgb = raw.postprocess()
imageio.imsave('F:\TripletLion\default.tiff', rgb)
print(rgb.dtype)
print(rgb.shape)On obtient
uint8
(4256, 2848, 3)
Analysons : Tout d’abord, la conversion d’une image RAW exige une phase de « pré-traitement » pour interpoler les plans de pixels capturés et reconstruire une matrice conventionnelle.
La commande « postprocess » accepte (entres-autres) un paramètre demosaic_algorithm=<valeur> qui permet de sélectionner différent modes de « debayerisation » : LINEAR, VNG, PPG, AHD, DCB, MODIFIED_AHD, AFD, VCD, VCD_MODIFIED_AHD, LMMSE, AMAZE, DHT, AAHD
Plusieurs de ces algorithmes se trouvent implémentés dans différents OpenSource, comme RawTherapee . Voir ce site pour ceux qui veulent en savoir plus. Mais attention : tous ne sont pas disponibles sous Windows, et mieux vaut tester avant…
for d in rawpy.DemosaicAlgorithm:
print(d.name, 'NOT' if d.isSupported is False
else 'possibly' if d.isSupported is None else '', 'supported')Mais dans quel format et qualité, tout cela ?
– rgb, à la lecture, sera un « objet » Rawpy sensé être à résolution maximale
– mais tous les autres formats, après dématriçage : 8 bits ! 🙁
C’est pas terrible pour le traitement, on passe de 12/14 bits à 8…
Donc, on va agir autrement :
path = 'F:\TripletLion\DSC1407.ARW'
with rawpy.imread(path) as raw:
raw_image = raw.raw_image.copy()
raw_colors=raw.raw_colors.copy()
print("raw_image shape",raw_image.shape)
print("raw_image max",raw_image.max())
print("raw_colors shape",raw_colors.shape)
print("raw_colors max",raw_colors.max())
raw.close()Et là, le résultat change
raw_image type uint16
raw_image shape (2848, 4288)
raw_image max 16596
raw_colors shape (2848, 4288)
raw_colors max 3
Ici, on récupère vraiment des informations 16 bits ! 🙂
Avec 1/4 des données : R, 2/4 : G et 1/4 B, dont on peut même récupérer les informations couleurs.
Si on veut accéder aux plans CFA de l’image, ceci est la bonne méthode.
Si c’est le résultat interpolé (donc en couleur « utilisable ») qui est visé, il suffit de rajouter le paramètre « output_bps=16 » au niveau de l’appel de postprocess().
Au sein de l’objet rawpy :
- La méthode raw_image : va accéder ces plans « natifs » de l’image,
- Bayer images = une ndarray 2D
- Foveon et autres = une ndarray 3D.
- Notez que s’il existe un 4 ème canal couleur, celui-ci sera obligatoirement à « 0 » (transparent)
- Remarque : si on modifie ce contenu « raw_image », le résultat issu du dématriçage sera évidemment affecté.
Mais on ne peut accéder ce contenu que dans le « with » avant d’appeler le close() et on va donc copier le contenu pour le traiter plus tard via raw_image = raw.raw_image.copy().
- La méthode raw_colors : va accéder une table d’incides couleur pour chaque pixel dans l’image. En fait, cela revient à exécuter un raw_color(y,x) sur chaque pixel de l’image.
Donc : il faut récupérer sans pré-traitement les plans images et les traiter sous cette forme pour garder le bon niveau de signal. Et si nécessaire, on fournira un format de « présentation » sous 8 bits en finale.
Pour sauver l’image :
Tout d’abord, comme déjà indiqué, examinons les paramètres avancé de raw.postprocess() Et tout spécialement output_bps=(8 or 16). En testant avec 16, on obtient
path = 'F:\TripletLion\DSC1407.ARW'
with rawpy.imread(path) as raw:
rgb = raw.postprocess(output_bps=16)
print(rgb.dtype)
print(rgb.shape)=> uint16 => (4256, 2848, 3)
Nous obtenons directement le bon format pour être sauvé par d’autres méthodes (selon le format cible). Attention cependant au stockage interne (RGB ou BGR), qu’il faudra soit-même inverser ou spécifier via un paramètre au niveau de l’écriture. Pour le reste, voir le topic suivant.
Sauver les images
Si vous avez parcouru les exemples ci-dessus, vous avez déjà la réponse…
Trois manières :
– OpenCV (imwrite)
– imageio (imsave)
– Os (write, writev) : un peu basique, mais cela peut par moment servir…
C’est plus selon le traitement que l’on va utiliser l’une ou l’autre…
L’évaluation est facile :
– ouvrir une image 16 ou 32 bits
– la sauver sous différents formats
– voir ce qui se passe…
Selon la documentation : « no problem… »
Avec imageio : testons une image RAW (en RGB)
import rawpy
import imageio
path = 'F:\TripletLion\DSC1407.ARW'
with rawpy.imread(path) as raw:
rgb = raw.postprocess(output_bps=16)
imageio.imsave('F:\TripletLion\DSC1407.tiff', rgb)
imageio.imsave('F:\TripletLion\DSC1407.png', rgb)
imageio.imsave('F:\TripletLion\DSC1407.jpeg', rgb)
imageio.imsave('F:\TripletLion\DSC1407.fits', rgb)Résultat, on voit apparaître des messages
Lossy conversion from uint16 to uint8. Losing 8 bits of resolution. Convert image to uint8 prior to saving to suppress this warning. Et pour "fits" : Traceback (most recent call last): OSError: FITS save handler not installed
Et le cas « fits » demande un examen supplémentaire… ok
A l’examen des images sauvées :
L’image TIFF est bien sauvée en 16bits, les autres sont bien en 8 bits…
Avec OpenCV : testons avec une image 32 bits
Remarque : il faut tenir compte des formats de stockage, 8 et 16 bits.
import cv2 as cv
import numpy as np
image = cv.imread('F:\TripletLion\Autosave.tif')
if image is None:
image = cv.imread('F:\TripletLion\Autosave.tif',-1)
#Convert to int 8 and 16 bits
image_uint16 = (image * 65536).astype("uint16")
image_uint8 = (image * 255).astype("uint8")
cv.imwrite('F:\TripletLion\Autosave_0.tiff', image_uint16)
print('tiff done')
cv.imwrite('F:\TripletLion\Autosave_0.png', image_uint16)
print('png done')
cv.imwrite('F:\TripletLion\Autosave_0.jpg', image_uint8)
print('jpeg done')La première précaution est de convertir les valeurs « float » vers des valeurs 16 et 8 bits plus standards. Les images sauvées sont cohérentes :

Tout est bon : les images PNG et TIFF sont bien en 16bits, l’image JPEG en 8 bits et le niveau de qualité cohérent.
cv.imwrite() est efficace 🙂
Sauver une image FITS
Comme présenté lors de la lecture d’une image FITS, le contenu de ce type de format peut être complexe…
Commençons par le plus simple, avec la sauvegarde d’une image.
De base, GIMP (2.10) peut facilement lire une image RAW (via DarkTable qui utilise libraw) et la sauver sous FITS. C’est une bonne référence pour vérifier si on a une programmation correcte.
Remarque : une image RAW de 12MB (SonyA7s), une fois debayerisée et sauvée sous FITS via GIMP fait en finale : 172MB !
Le « header » (lisible dans le fichier) indique plusieurs choses intéressantes.
FITS a 53 « mots clés » autorisés :
This data dictionary lists the 53 keywords currently defined in the FITS Standard: (blank) CROTAn EQUINOX NAXISn TBCOLn TUNITn AUTHOR CRPIXn EXTEND OBJECT TDIMn TZEROn BITPIX CRVALn EXTLEVEL OBSERVER TDISPn XTENSION BLANK CTYPEn EXTNAME ORIGIN TELESCOP BLOCKED DATAMAX EXTVER PCOUNT TFIELDS BSCALE DATAMIN GCOUNT PSCALn TFORMn BUNIT DATE GROUPS PTYPEn THEAP BZERO DATE-OBS HISTORY PZEROn TNULLn CDELTn END INSTRUME REFERENC TSCALn COMMENT EPOCH NAXIS SIMPLE TTYPEn
Dans notre cas, issu de GIMP, nous avons :
SIMPLE = T BITPIX = -32 NAXIS = 3 NAXIS1 = 2848 NAXIS2 = 4256 NAXIS3 = 3 BZERO = 0 BSCALE = 1 DATAMIN = 0 DATAMAX = 1 HISTORY THIS FITS FILE WAS GENERATED BY GIMP USING FITSRW COMMENT FitsRW is (C) Peter Kirchgessner (peter@kirchgessner.net), but availableCOMMENT under the GNU general public licence. COMMENT For sources see http://www.kirchgessner.net COMMENT Image type within GIMP: GIMP_RGB_IMAGE COMMENT Sequence for NAXIS3 : RED, GREEN, BLUE END ...
Si on décode :
SIMPLE = T => indique que c'est conforme au standard général BITPIX = -32 => le type de données, ici -32 = float 32 NAXIS = 3 => nombre d'axes des données NAXIS1 = 2848 => nombre de valeurs par lignes (= width) NAXIS2 = 4256 => nombre de Lignes (= height) NAXIS3 = 3 => 3 ème axe, profondeur (= levels, RGB ici) BZERO = 0 => base "shift", pour support unsigned (ici 0) BSCALE = 1 => linéaire (x1 sur toutes les valeurs) DATAMIN = 0 => valeur minimale DATAMAX = 1 => valeur maximale HISTORY THIS FITS FILE WAS GENERATED BY GIMP USING FITSRW COMMENT FitsRW is (C) Peter Kirchgessner (peter@kirchgessner.net), but available COMMENT under the GNU general public licence. COMMENT For sources see http://www.kirchgessner.net COMMENT Image type within GIMP: GIMP_RGB_IMAGE COMMENT Sequence for NAXIS3 : RED, GREEN, BLUE END => Obligatoire... ...
Remarque : pour aider dans le domaine FITS, j’utilise des « Fits Viewer », avec deux outils assez différents :
AvisFV
Qui utilise les même librairies que le logiciel AstroArt et donne une vue « intuitive » du contenu
FV : Fits viewer & editor développé au « High Energy Astrophysics Science Archive Research Center » (HEASARC) de la NASA / GSFC.
Deux vues largement différentes de la même chose…
Une vue « photo et pixels » : orientée vers le visuel de l’image
Une vue « science et tables » ; orientée vers les données
La dualité de FITS… 🙂 A laquelle il faut arriver au même résultat par programmation…
Avec les deux modes disponibles :
– mode « image » (on encapsule les données et on écrit)
– mode « table » (on décompose les informations avant d’écrire de fermer)
Partons de l’image RAW (topic précédent)…
Après rgb = raw.postprocess(output_bps=16), nous obtenons une ndarray de (4256, 2848, 3)
D’après le header FITS, il nous faudrait
NAXIS = 3 => nombre d'axes des données
NAXIS1 = 2848 => nombre de valeurs par lignes (= width)
NAXIS2 = 4256 => nombre de Lignes (= height)
NAXIS3 = 3 => 3 ème axe, profondeur (= levels, RGB ici)
Si on code un simple :
from astropy.io import fits
import rawpy
path = 'F:\TripletLion\DSC1407.ARW'
with rawpy.imread(path) as raw:
rgb = raw.postprocess(output_bps=16)
#Create a "Primary" HDU object to store image
hdu = fits.PrimaryHDU(rgb)
#Create a HDUList to indicate the PRIMARY contents
hdulist = fits.HDUList([hdu])
#Write the file... method 1
hdulist.writeto('F:\TripletLion\DSC1407_v1.fits')On observe le résultat (via fv) sur DSC1407_v1.fits…
Il n’est pas celui espéré 🙁
SIMPLE = T / conforms to FITS standard
BITPIX = 16 / array data type
NAXIS = 3 / number of array dimensions
NAXIS1 = 3
NAXIS2 = 2848
NAXIS3 = 4256
EXTEND = T
BSCALE = 1
BZERO = 32768
END
Si on a des valeurs int 16 avec BZERO = 32768, si on ajoute BSCALE = 1 => on obtient du uint 16 bits : ok….
Mais une image de 3 pixels par ligne, 2848 lignes et dans 4256 niveaux, il y a un problème… 🙂 A l’origine, c’est une ndarray de (4256,2848,3), mais selon la documentation de FITS :
« Image/array data as a ndarray.
Please remember that the order of axes on an Numpy array are opposite of the order specified in the FITS file. For example for a 2D image the “rows” or y-axis are the first dimension, and the “columns” or x-axis are the second dimension. » => 🙁 mais RTFM :-)… Donc…
from astropy.io import fits
import rawpy
import numpy as np
path = 'F:\TripletLion\DSC1407.ARW'
with rawpy.imread(path) as raw:
rgb = raw.postprocess(output_bps=16)
print("rgb =",rgb.shape)
#in RAW sample (4256 2848 3)
nbr_valbyrow,nbr_rows,depth = rgb.shape
# image cible, must be (3 2848 4256)
rgb_fits = np.zeros((depth,nbr_rows,nbr_valbyrow),dtype="uint16")
for level in range(0,depth):
for nbval in range(0,nbr_valbyrow):
for row in range(0,nbr_rows):
rgb_fits[level,nbval,row]=rgb[nbval,row,level]
print("rgb_fits =",rgb_fits.shape)
#Create a "Primary" HDU object to store image
hdu = fits.PrimaryHDU(rgb_fits)
#Create a HDUList to indicate the PRIMARY contents
hdulist = fits.HDUList([hdu])
#Write the file... method 1
hdulist.writeto('F:\TripletLion\DSC1407_v1.fits')
print('Fits 1 done')
#Write the file... method 2
hdu.writeto('F:\TripletLion\DSC1407_v2.fits')
print('Fits 2 done')
#Write the file... method 3
fits.writeto('F:\TripletLion\DSC1407_v3.fits',rgb_fits)
print('Fits 3 done')Ok, il y a moyen de faire plus subtil, au niveau code, avec Numpy… 🙂
Mais voyons les images… Au niveau « Fits Header », cela colle…
SIMPLE = T / conforms to FITS standard
BITPIX = 16 / array data type
NAXIS = 3 / number of array dimensions
NAXIS1 = 2848
NAXIS2 = 4256
NAXIS3 = 3
EXTEND = T
BSCALE = 1
BZERO = 32768
END
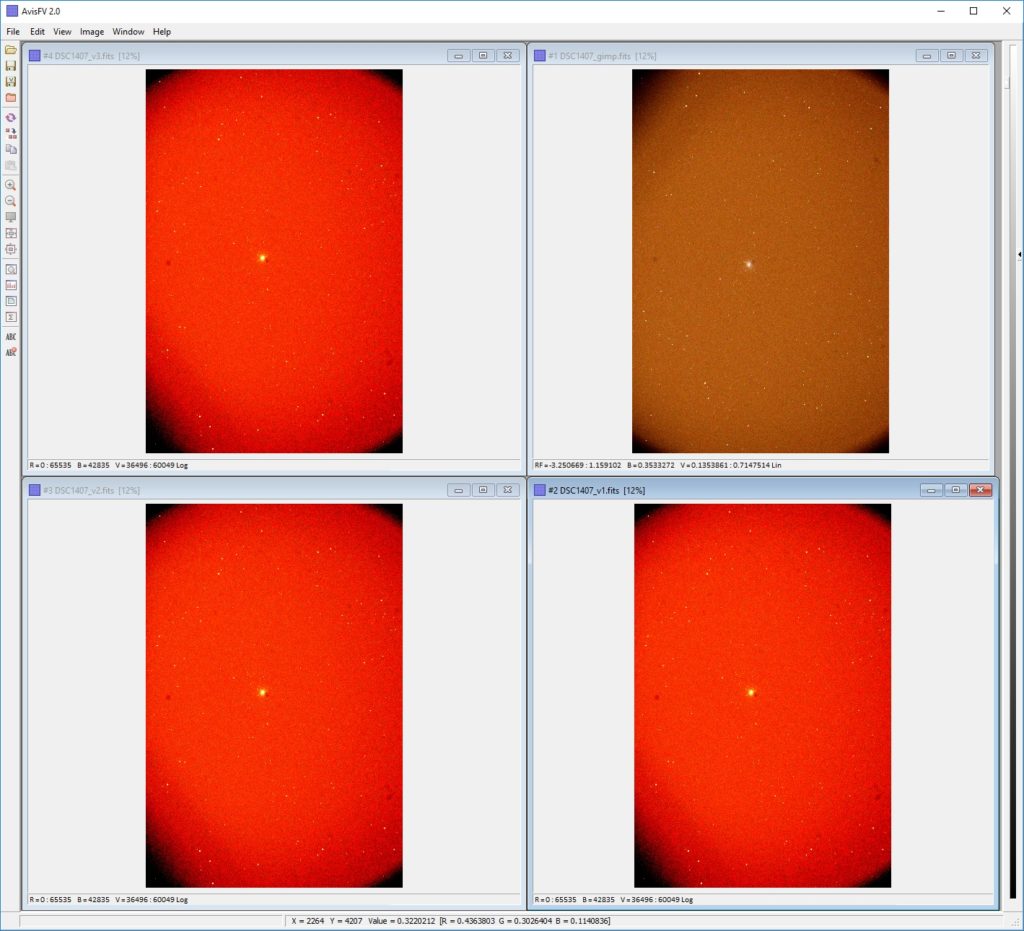
Niveau format : ok…
Niveau présentation : ok
Perte entre 32 et 16 bits : ok
Couleur : bizarre, mais cela sera traité dans un prochain sujet.
Remarque : dans les autres méthodes d’écriture présentées ici, on écrase les précédentes version sans aucun message. Mais ici, la méthode fits.writeto() sur une image qui est déjà présente retourne :
OSError: File ‘F:\TripletLion\DSC1407_v1.fits’ already exists.
Donc, un bout de code peut aider dans le cas de traitement répétitif.
Soit
pyfits.writeto(..., clobber=True) => écrase, mais il reste un message
Soit
pyfits.writeto(..., overwrite=True) => idem, sans message Lire/sauver le format webp
Quels avantages à gérer ce format qui n’est que très peu reconnu par les logiciels d’imagerie ? Deux principaux :
- La présentation (finale) des travaux sur un site web, permettant d’exploiter une qualité d’image meilleure que JPEG.
Quand on y réfléchit : à quoi cela sert de passer des heures à traiter en 32 bits et milliers de niveaux (donc des images de plusieurs dizaine, voire centaine de MB) et … tout afficher du 8 bits en compression JPEG maximale dès que l’on veut la montrer sur un site ? - Les animations basées sur des images (time lapse et autres). Actuellement le format GIF (historique de l’époque « Compuserve » et des modems à 32kbits) commence à montrer des faiblesses et surtout face à la montée de qualité des images…
Ce format est « développé » et « prévu » pour le web.. Donc, tous les « browsers » le supportent dans ses 3 formats internes : avec pertes, sans pertes, animations.
Au niveau Python, il est supporté par deux libraires : la librairie webp et webptools installés de manière classique (« pip install webp »).
Et on dispose de méthodes spécifiques au format pour gérer :
- La conversion/encodage vers le format interne
- Le décodage vers un autre format
- Compression (aucune ou valeur)
- Métadonnées
- Transparence / Channel Alpha
- Profil couleur (type ICC)
- Animation
Les « webptools » sont une série d’outils utilisables tel quels que cwebp (convert to webp)
from webptools import webplib as webp
# pass input_image(.jpeg,.pnp .....) path ,
# output_image(give path where to save and image file name with .webp file type extension)
print(webp.cwebp("python_logo.jpg", "python_logo.webp", "-q 80"))
Pour évaluer tout ceci, définissons une image « test »

Qui combine pas mal d’éléments intéressants, et on la crée sous plusieurs formats courants :
Taille Formats
938 352 Test16bits.jpf
428 666 Test16bits.png
2 396 854 Test16bits.psd
3 531 456 Test16bits.tif
3 024 760 Test32bits.tif
139 051 Test8bits.jpg
291 462 Test8bits.png
1 253 253 Test8bits.psdLe premier est la taille de la même image
– le PSD plus important est normal, il inclut des calques
– en 8 bits, JPEG est le plus léger, comme on s’y attendait, mais avec une destruction de l’image.
– en 16 bits, on va utiliser le JPEG2000 et c’est PNG qui est le plus léger
– le tiff (non destructeur et sans compression) est toujours le plus gros, mais la version 32 bits (float) est plus petite que la 16 bits (uint).
Convertissons vers webp… Les résultats sont impressionnants :
import webp
from PIL import Image
im8a = Image.open("D:\\$python\\Webp\\test8bits.jpg").convert("RGB")
webp.save_image(im8a,"D:\\$python\\Webp\\test8bitsFromJpeg.webp",quality=100)
im8b = Image.open("D:\\$python\\Webp\\test8bits.png").convert("RGB")
webp.save_image(im8b,"D:\\$python\\Webp\\test8bitsFromPNG.webp",quality=100)
Le résultat :
Taille Origine
46 828 test8bitsFromJpeg.webp
44 470 test8bitsFromPNG.webpOn passe, dans le meilleur cas de départ, de environ 139KB (Jpeg 8bits) à environ 46KB, soit : -66% ! Avec un « quality=100 ».. Cela veut dire quoi ?
L’outil cwebp dispose d’une liste impressionnante d’options :
– une série influençant le « lossless »
– l’autre influençant le « lossy »
– et en finale de nombreuses options liées au PSNR et SSIM (un sujet sur lequel on reviendra)
Et parfois, c’est pas trop clair que les influences croisées…
Donc, testons…
import os
import webp
from PIL import Image
print("Original size : \t",os.path.getsize("D:\\$python\\Webp\\test8bits.png"))
im8a = Image.open("D:\\$python\\Webp\\test8bits.png").convert("RGB")
webp.save_image(im8a,"D:\\$python\\Webp\\test8bitsFromPNG_default.webp")
print("Default size : \t",os.path.getsize("D:\\$python\\Webp\\test8bitsFromPNG_default.webp"))
im8a = Image.open("D:\\$python\\Webp\\test8bits.png").convert("RGB")
webp.save_image(im8a,"D:\\$python\\Webp\\test8bitsFromnPNG_q100.webp",quality=100)
print("Quality=100 size : \t",os.path.getsize("D:\\$python\\Webp\\test8bitsFromnPNG_q100.webp"))
im8a = Image.open("D:\\$python\\Webp\\test8bits.png").convert("RGB")
webp.save_image(im8a,"D:\\$python\\Webp\\test8bitsFromPNG_q0.webp",quality=0)
print("Quality=0 size : \t",os.path.getsize("D:\\$python\\Webp\\test8bitsFromPNG_q0.webp"))
im8a = Image.open("D:\\$python\\Webp\\test8bits.png").convert("RGB")
webp.save_image(im8a,"D:\\$python\\Webp\\test8bitsFromPNG_lossless.webp",lossless=True)
print("Lossless size : \t",os.path.getsize("D:\\$python\\Webp\\test8bitsFromPNG_lossless.webp"))
im8a = Image.open("D:\\$python\\Webp\\test8bits.png").convert("RGB")
webp.save_image(im8a,"D:\\$python\\Webp\\test8bitsFromPNG_Nolossless.webp",lossless=False)
print("No lossless size : \t",os.path.getsize("D:\\$python\\Webp\\test8bitsFromPNG_Nolossless.webp"))Résultat :
Original size : 291462
Default size : 9352
Quality=100 size : 44470
Quality=0 size : 1550
Lossless size : 197532
No lossless size : 9352Encore plus surprenant… On passe de 291KB à 9KB, voire 1.5KB !!!
(soit une compression de 95% !!!)
Mwais, examinons en détails… On va ouvrir cela via GIMP et comparer…

Et là, on commence à comprendre…
- Quality = 0 : la dégradation est clairement visible, donc : inexploitable, sauf dans des cas extrêmes (image unie, par exemple)
- Quality > 0 et <100 : il faudrait tester (en boucle) pour estimer le sauvetage sur des images plus complexes.
- NoLossless : équivalent à la configuration par défaut. Et en soi, avec env 10KB, un bon résultat sur les zones « gradient » (qui sont compressée à leur plus simple expression), il faudra examiner avec des images plus complexes.
- Quality = 100 et lossless : faudra comparer avec l’original !
Prenons une autre image, plus complexe, mais gardons le 8 bits à ce stade…

import os
import webp
from PIL import Image
print("Original size : \t",os.path.getsize("D:\\$python\\Webp\\rosette.tiff"))
im8a = Image.open("D:\\$python\\Webp\\rosette.tiff").convert("RGB")
webp.save_image(im8a,"D:\\$python\\Webp\\rosette8bitsFromPNG_default.webp")
print("Default size : \t",os.path.getsize("D:\\$python\\Webp\\rosette8bitsFromPNG_default.webp"))
webp.save_image(im8a,"D:\\$python\\Webp\\rosette8bitsFromnPNG_q100.webp",quality=100)
print("Quality=100 size : \t",os.path.getsize("D:\\$python\\Webp\\rosette8bitsFromnPNG_q100.webp"))
webp.save_image(im8a,"D:\\$python\\Webp\\rosette8bitsFromPNG_q0.webp",quality=0)
print("Quality=0 size : \t",os.path.getsize("D:\\$python\\Webp\\rosette8bitsFromPNG_q0.webp"))
webp.save_image(im8a,"D:\\$python\\Webp\\rosette8bitsFromPNG_lossless.webp",lossless=True)
print("Lossless size : \t",os.path.getsize("D:\\$python\\Webp\\rosette8bitsFromPNG_lossless.webp"))
webp.save_image(im8a,"D:\\$python\\Webp\\rosette8bitsFromPNG_Nolossless.webp",lossless=False)
print("No lossless size : \t",os.path.getsize("D:\\$python\\Webp\\rosette8bitsFromPNG_Nolossless.webp"))Original size : 214276480
Default size : 10954690
Quality=100 size : 46885724
Quality=0 size : 391700
Lossless size : 124874332
No lossless size : 10954690Comparaison finale, question taille :
| Test 1 | Rosette | % | % | -% | -% | ||
| Original | 291 462 | 214 276 480 | 100,00 | 100,00 | 0,00 | 0,00 | |
| Default | 9 352 | 10 954 690 | 3,21 | 5,11 | 96,79 | 94,89 | |
| Quality=100 | 44 470 | 46 885 724 | 15,26 | 21,88 | 84,74 | 78,12 | |
| Quality=0 | 1 550 | 391 700 | 0,53 | 0,18 | 99,47 | 99,82 | |
| Lossless | 197 532 | 124 874 332 | 67,77 | 58,28 | 32,23 | 41,72 | |
| NoLossless | 9 352 | 10 954 690 | 3,21 | 5,11 | 96,79 | 94,89 | |
| Original_JPEG | 134 439 099 | 62,74 | 37,26 | ||||
| Original_J2K | 154 748 785 | 72,22 | 27,78 |
A ce stade…
- L’image de base (PNG) pèse 214MB, « lourd » pour la publier…
- Les conversion classiques (vers JPEG et JPEG2000), en conservant le niveau de détails maximal (qualité 100 et « lossless » pour J2K) nécessite respectivement 134 et 154 MB (soit 62 et 72% de la taille orginelle)
- Les conversions vers webp l’emportent dès le départ, avec un score supérieur de 90% dans la conversion « par défaut »… Et même la conversion LossLess est inférieure au JEPG2000.
Quant à la qualité… Entre 214MB et 10 MB… C’est bluffant.

Visuellement, il va falloir chercher… Donc, il faudra analyser le contenu autrement pour détecter les différences. Cela sera le contenu d’un dossier spécifique…
A ce stade, en 8bits : il y a clairement visiblement intérêt à utiliser le format webp pour présenter nos travaux d’astrophotographie.
Les exemples pour se faire une opinion ?
- En 8 bits, l’image originale en TIFF
- En 8bits, depuis PNG, compression par défaut
- En 8bits, depuis PNG, Quality=100
- En 8 bits, depuis PNG, Quality = 0
- En 8 bits, depuis PNG, « lossless » ou « sans perte »
- En 8 bits, depuis PNG, « no lossless » = compression
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Quant à l’utiliser pour les traitements : peu de logiciel « astro » supportent le format webp, de nos jours. Reste Python 🙂 Et donc, peut être intéressant si les données 16bits sont aussi bien conservées.
Pour lire du 16bits et convertir ? On va reprendre la méthode déjà présentée… Car là, PIL ne supporterait pas la charge…
Et dans CV2, on trouve d’ailleurs une documentation incluant webp
et Python: cv.IMWRITE_WEBP_QUALITY devrait permettre de tester l’influence de la qualité de compression (par defaut = 60).
import os
import os
import webp
import cv2 as cv
import numpy as np
image_32 = cv.imread('D:\\$python\\Webp\\Autosave.tif', -1)
print("Image type : ",image_32.dtype)
print("Image size :",image_32.shape)
#CV2 convert original values to float value (range [0..1], 1 = original 65535)
print("Image values range : from ",image_32.min()," to ",image_32.max())
print("Image mean value : ",image_32.mean())
print("Original size : \t",os.path.getsize("D:\\$python\\Webp\\Autosave.tif"))
cv.imwrite("D:\\$python\\Webp\\Autosave32bitsFromTIFF_default.webp",image_32,[int(cv.IMWRITE_WEBP_QUALITY), 100])
print("Default size : \t",os.path.getsize("D:\\$python\\Webp\\Autosave32bitsFromTIFF_default.webp"))Image type : float32
Image size : (3353, 5164, 3)
Image values range : from 6.833779e-06 to 0.99609375
Image mean value : 0.018040543
Original size : 166249306
Default size : 30912Oups ? De 166MB à 30 KB ???
Le contenu est très bizarre… En 8bits et évidemment : inexploitable…
Ok, va reprendre les tests avec l’image de la Rosette, mais sauvée (via GIMP) en 16 et 32bits.
import os
import webp
import cv2 as cv
import numpy as np
image_16 = cv.imread('D:\\$python\\Webp\\rosette_16bits.tif', -1)
image_temp=image_16
print("Image type : ",image_16.dtype)
print("Image size :",image_16.shape)
print("Image values range : from ",image_16.min()," to ",image_16.max())
print("Image mean value : ",image_16.mean())
image_temp[:,:,2] = image_16[:,:,0] #(bgr)B > (rgb)B
image_temp[:,:,1] = image_16[:,:,1] #(bgr)G > (rgb)G
image_temp[:,:,0] = image_16[:,:,2] #(bgr)R > (rgb)R
image_16 = image_temp
print("Original size : \t",os.path.getsize("D:\\$python\\Webp\\rosette_16bits.tif"))
cv.imwrite("D:\\$python\\Webp\\rosette_16bits.tifFromTIFF_default.webp",image_16,[int(cv.IMWRITE_WEBP_QUALITY), 90])
print("Default size : \t",os.path.getsize("D:\\$python\\Webp\\rosette_16bits.tifFromTIFF_default.webp"))
image_32 = cv.imread('D:\\$python\\Webp\\rosette_32bits.tif', -1)
image_temp=image_32
print("Image type : ",image_32.dtype)
print("Image size :",image_32.shape)
print("Image values range : from ",image_32.min()," to ",image_32.max())
print("Image mean value : ",image_32.mean())
image_temp[:,:,2] = image_32[:,:,0] #(bgr)B > (rgb)B
image_temp[:,:,1] = image_32[:,:,1] #(bgr)G > (rgb)G
image_temp[:,:,0] = image_32[:,:,2] #(bgr)R > (rgb)R
image_32 = image_temp
print("Original size : \t",os.path.getsize("D:\\$python\\Webp\\rosette_32bits.tif"))
cv.imwrite("D:\\$python\\Webp\\rosette_32bits.tifFromTIFF_default.webp",image_32,[int(cv.IMWRITE_WEBP_QUALITY), 90])
print("Default size : \t",os.path.getsize("D:\\$python\\Webp\\rosette_32bits.tifFromTIFF_default.webp"))
Image type : uint16
Image size : (8450, 8450, 3)
Image values range : from 0 to 65535
Image mean value : 15475.131116865656
Original size : 428440704
Default size : 12566048
Image type : float32
Image size : (8450, 8450, 3)
Image values range : from -6.556511e-06 to 1.0000066
Image mean value : 0.08319896
Original size : 856858800
Default size : 132782En uint16, on passe de 428MB à 125MB
En float32, de 856MB à 132KB !
Mais quoi qu’il en soit : de cette manière, forget it…
Donc, à ce stade : mieux vaut utiliser ce format pour ce qu’il est parfaitement adapté : la présentation sur le web (en 8bits)… On y reviendra.