
Voici quelques utilitaires destinés à simplifier la vie de toute utilisateur de Evscope désireux de garder/traiter ses images.
Cet article traite des images fournies par l’Evscope V1 et Equinox 1, des adaptations seront nécessaires pour les V2 (pas la même taille d’image).
On va post-traiter les images directement issues des fonctions standard de « sauvegarde » de l’APP Dans un autre article, on s’occupera des images « brutes » reçues via « export » depuis le site de Unistellar.
La première tâche à faire, quand on a fini une soirée d’observation, c’est de ranger ses images…
Et dans le cas de l’Evscope, ce n’est pas le plus simple : 4 types d’images, pas d’informations pertinentes, une seule information certaine (si on est sous Android) : l’heure de capture…
Donc, même si on a pris des notes, cela prend du temps ! (et on peut facilement se tromper…)
Depuis la V2.x de l’APP, on peut désormais sauver en même temps les deux images (Crop et Full) avec des noms différents, mais cela reste sous des noms « techniques » et peu reconnaissables directement, car en fin de capture, on obtient toujours donc un « tas » d’images sous le format :
eVscope-aaaammdd-hhmmss.png (rem : aaaammdd-hhmmss est fournit en UTC)
ex : eVscope-20220105-020042.png
Objectif n°1 : trier les images
Trois problèmes se posent :
– identifier le type de l’image
– préparer les images pour la suite
Comme depuis la version 2.x de l’APP, c’est plus simple (avant, il fallait traiter les duplicatas et gérer deux sub-dir à l’entrée), on va donc organiser cela via un petit programme qui va partir d’une sub-dir « maître » (du genre date+lieu d’observation) dans laquelle on crée une subdir input et on y stocke toutes les images venant de la Tablette.
Ensuite, le programme suivant va trier les images par type, les convertir au format tiff et les stocker dans des sub-dir séparées. Le code est très simple et ne demande guère de commentaires.
# -*- coding: utf-8 -*-
"""
Created on Fri Jul 6 11:30:25 2018
This program analyzes eVscope / equinox V1 provided images :
- determines its type
- adjusts some characteristics
- converts them to tiff format
- saves them in separate sub-dirs
@author: TTFonWeb
"""
import glob
import os
import imageio
import datetime
import skimage.io
#Define functions
#****************************************
def AnalyseImage(im,name,Debug=False):
#Analyse image and determines main characteristics
#Extract size, determine eVscope type, extract capture date
h,w,c = im.shape
#Determine eVscope type
width={2240:"crop",2560:"full",1280:"base",1120:"cropbase",0:"undefined"}
height={2240:"crop",1920:"full",960:"base",1120:"cropbase",0:"undefined"}
imagetype=width[0]
for t in width:
if t == w :
imagetype=width[t]
#Extract capture date
capture_date = name.split("eVscope-")[1].split(".")[0]
return w,h,imagetype,capture_date
def ValidateSubdir(path,Debug=False):
#Scan for needed sub-dirs and build them if needed...
status=True
msg=""
if not os.path.exists(path):
msq = path+"is not present"
status=False
if not os.path.exists(path+"\\input\\observator"):
msq = path+"\input\observator is not present"
status=False
if not os.path.exists(path+"\\input\\operator"):
msq = path+"\input\operator is not present"
status=False
if not os.path.isdir(path+"\\output"):
print('The directory : output is not present. Creating a new one..')
os.mkdir(path+"\\output")
if not os.path.isdir(path+"\\output\\full"):
print('The directory : full is not present. Creating a new one..')
os.mkdir(path+"\\output\\full")
if not os.path.isdir(path+"\\output\\crop"):
print('The directory : crop is not present. Creating a new one..')
os.mkdir(path+"\\output\\crop")
if not os.path.isdir(path+"\\output\\base"):
print('The directory : base is not present. Creating a new one..')
os.mkdir(path+"\\output\\base")
if not os.path.isdir(path+"\\output\\cropbase"):
print('The directory : cropbase is not present. Creating a new one..')
os.mkdir(path+"\\output\\cropbase")
if not os.path.isdir(path+"\\output\\debug"):
print('The directory : debug is not present. Creating a new one..')
os.mkdir(path+"\\output\\debug")
if not os.path.isdir(path+"\\output\\undefined"):
print('The directory : undefined is not present. Creating a new one..')
os.mkdir(path+"\\output\\undefined")
return status,msg
#Start of program
#****************************************
#running parameters
#Debug=True
Debug=False
path=""
path_out=""
#Modified paths values
#drive name
drive = "I:"
#main path of images data
path = drive+"\\$Photo_Astro\\20220111-13_France"
#Mandatory subdirs
#input subdir : receives all images for capture night
path_in = path + "\\input"
#mandatory subdirs
#input/observator : receives all enhanced vision in annotation (circle) mode
#input/operator : receives all enhanced vision in full (2x upscaled) mode
#output subdir : automaticcaly build, will receive all images after sorting
path_out = path + "\\output"
#computed subdirs for all image types
#output/full, output/base, output/crop; output/cropbase
#if not defined in program, ask it
if path_in=="":
path_in = input('Enter input subdir pathname : ')
if path_out=="":
path_out = input('Enter output subdir pathname : ')
#verify sub-dir information or build necessary files
status,msg = ValidateSubdir(path,Debug)
if status:
print("All sub-dirs are ok, start processing")
else:
print(msg+", aborting program")
exit()
SupportedInputType =["png"]
#open log file
log=open(path+"\\TTFonWeb_eVscope_SortImages_runlog.txt","w")
now = datetime.datetime.now()
print ("> Current date and time : ",now.strftime("%Y-%m-%d %H:%M:%S"))
log.write("#eVscope_SortImages V1.1, run : " + now.strftime("%Y-%m-%d %H:%M:%S")+"\n")
log.write(">Operator input sub_dir : "+ path_in + "\\operator"+"\n")
log.write(">Observator input sub_dir : "+ path_in + "\\observator"+"\n")
imagefiles=[]
#Global scan of subdirs
for type in SupportedInputType:
for file in glob.glob(path_in + "\\operator\\eVscope-*" + type):
imagefiles.append(file)
count_operator=len(imagefiles)
log.write("> "+str(count_operator) + " Operator image file(s) to process"+"\n")
for file in glob.glob(path_in + "\\observator\\eVscope-*" + type):
imagefiles.append(file)
count_observator=len(imagefiles)-count_operator
log.write("> "+str(count_observator) + " Observator image file(s) to process"+"\n")
if len(imagefiles) > 0:
print("> Total : " + str(len(imagefiles)) + " image file(s) to process"+"\n")
max_image_count = len(imagefiles)
count_full=0
count_crop=0
count_cropbase=0
count_base=0
count_undef=0
#For each found image
print("Step 1 - Analyze & sort image files")
log.write("#Step 1 - Analyze & sort image files"+"\n")
for file in imagefiles:
if os.name == "posix":
name = file.split('/')
else:
name = file.split('\\')
if len(name) > 0:
name = name[len(name)-1]
im = skimage.io.imread(file)
w,h,image_type,capture_date = AnalyseImage(im,name)
print("File : " + name + " > Type : " + image_type)
#Anyway, convert and store it at correct place with standardized name
if image_type != "undefined":
if image_type == "full":
count_full+=1
elif image_type == "crop":
count_crop+=1
if im.shape[2] == 4:
#suppress alpha channel 32 bits => 24 bits RGB
im = im[:,:,0:3]
print("Convert alpha layer",im.shape)
elif image_type == "cropbase":
count_cropbase+=1
if im.shape[2] == 4:
#im = skimage.color.rgba2rgb(im)
im = im[:,:,0:3]
print("Suppress alpha layer, final ",im.shape)
elif image_type == "base":
count_base+=1
else:
print("error in image type")
exit()
target_name = path_out + "\\"+image_type+"\\"+image_type+"_"+capture_date+"_orig.tif"
imageio.imsave(target_name,im)
else:
target_name = path_out + "\\"+image_type+"\\"+image_type+"_"+capture_date+"_orig.jpg"
imageio.imsave(target_name,im)
count_undef+=1
print("> save : " + target_name)
print("Output subdir : "+path_out)
print("Sorted images - \\full : "+str(count_full))
print("Sorted images - \\crop : "+str(count_crop))
print("Sorted images - \\base : "+str(count_base))
print("Sorted images - \\cropbase : "+str(count_cropbase))
print("Sorted images - \\undefined : "+str(count_undef))
print("Total images : "+str(count_full+count_crop+count_base+count_cropbase+count_undef))
log.write("#Output subdir : "+path_out+"\n")
log.write(">Sorted images - \\full : "+str(count_full)+"\n")
log.write(">Sorted images - \\crop : "+str(count_crop)+"\n")
log.write(">Sorted images - \\base : "+str(count_base)+"\n")
log.write(">Sorted images - \\cropbase : "+str(count_cropbase)+"\n")
log.write(">Sorted images - \\undefined : "+str(count_undef)+"\n")
log.write(">Total images : "+str(count_full+count_crop+count_base+count_cropbase+count_undef)+"\n")
else:
log.write("No image file(s) to process"+"\n")
print("No images found")
now = datetime.datetime.now()
print ("> Current date and time : ",now.strftime("%Y-%m-%d %H:%M:%S"))
log.write("#eVscope_SortImages V1.1, end : " + now.strftime("%Y-%m-%d %H:%M:%S")+"\n")
log.close()Le fichier log (TTFonWeb_eVscope_SortImages_runlog.txt) décrit les phases exécutées
#TTfonWeb eVscope_SortImages V1.1, run : 2022-01-17 06:10:41
>Operator input sub_dir : I:\$Photo_Astro\20220105-EvscopeAtHome\input\operator
>Observator input sub_dir : I:\$Photo_Astro\20220105-EvscopeAtHome\input\observator
#77 Operator image file(s) to process
#15 Observator image file(s) to process
#Step 1 - Analyze & sort image files
#Output subdir : I:\$Photo_Astro\20220105-EvscopeAtHome\output
>Sorted images - \full : 59
>Sorted images - \crop : 15
>Sorted images - \base : 18
>Sorted images - \cropbase : 0
>Sorted images - \undefined : 0
>Total images : 92Voila, la première partie est faite… Cela va déjà beaucoup plus rapidement !
Objectif n°2 : les renommer avec un nom plus facile
– identifier le type de l’image
– renommer l’image avec me nom de l’objet observé
Il suffit de lire les metadata de l’image pour y arriver, me direz-vous ?
Mwais, si c’était si simple… J’ai un article dédié sur le sujet.
Donc, voyons autrement… Comment passer du contenu d’un fichier image, tel que :

à « crop_20220105-054544_orig_M57_Ring-Nebula_7min_JANV052022.tif » qui sera plus parlant, et évidemment sans passer du temps à le faire manuellement ?
Simple : tout est dans l’image !
Deux défis à relever : rendre le texte courbe « rectiligne » et le reconnaître… Mais en Python, c’est relativement facile à faire… 🙂
Rendre un texte « courbe » rectiligne : une manière simple…
Si on regarde la théorie concernant le « curved text linearization », on trouve des méthodes assez sophistiquées pour résoudre tous les cas de figures… Mais ici, on va faire plus simple en ne s’attaquant que à ce cas particulier.
Première étape : Convertir l’image en niveau de gris et l’inverser… On va utiliser OpenCv pour régler cela… Et au cas où, on prévoit le cas où il resterait des images avec un « canal alpha » (4 plans) qui traîne… Cela se fait rapidement via :
img_rgb = cv.imread(file)
if img_rgb.shape[2] == 4:
img_gray = cv.bitwise_not(cv.cvtColor(skimage.color.rgba2rgb(img_rgb), cv.COLOR_BGR2GRAY))
else:
img_gray = cv.bitwise_not(cv.cvtColor(img_rgb, cv.COLOR_BGR2GRAY))Ce qui nous donne :

Deuxième étape : en regardant les images, s’imaginer en train de regarder qu’une petite partie de la courbe… Ex sur une autre image ;


On dispose d’un « N » parfaitement droit (en tout cas, assez que pour être reconnu sans peine). Idem avec un chiffre, tel le « 5 » plus loin…

Donc, il suffit de faire défiler les caractères derrière cette « lucarne » pour récupérer ceux-ci quasi horizontaux et lisibles. Un exemple en recherchant le prochain « N » dans une image ayant subi une rotation :

Dont acte… On commence par faire tourner l’image de -90° pour récupérer tous les caractères (on démarre dans la « ligne ») et on va ensuite extraire dans l’ordre : ligne, logo Unistellar, texte utile et ligne…
De nouveau, OpenCV nous fournit tous les outils nécessaires :
# initial rotate our image by -90 degrees around the center of the image
M = cv.getRotationMatrix2D((cX, cY), 90, 1.0
img_gray = cv.warpAffine(img_gray, M, (w, h))
#rotation allowed angle, 0 to 179 by 1
allowed_angle = np.arange(0, 180, 1, dtype=int)
angle=0
cpt_area=0
#will receive all image cropped elements
list_cutimages=[]
#sw to manage final image creation on cut shape size
defined=False
for angle in allowed_angle:
if angle > 0:
(h, w) = img_gray.shape[:2]
(cX, cY) = (w // 2, h // 2)
M = cv.getRotationMatrix2D((cX, cY), -angle, 1.0)
rotated = cv.warpAffine(img_gray, M, (w, h))
else:
rotated = img_gray
#crop area is fixed acording image type... here for "large crop image"
cut_image = rotated[2127:2192, 1083:1127]
list_cutimages.append(cut_image)
if not defined:
final_image = np.zeros([cut_image.shape[0],cut_image.shape[1]*200],dtype=int) + 255
final_image, nextpos = AssembleImage(final_image,0,cut_image)
defined=True
else:
final_image, nextpos = AssembleImage(final_image,nextpos,cut_image)
Ce qui nous donne (en laissant tomber la ligne) ce qu’il nous faut…
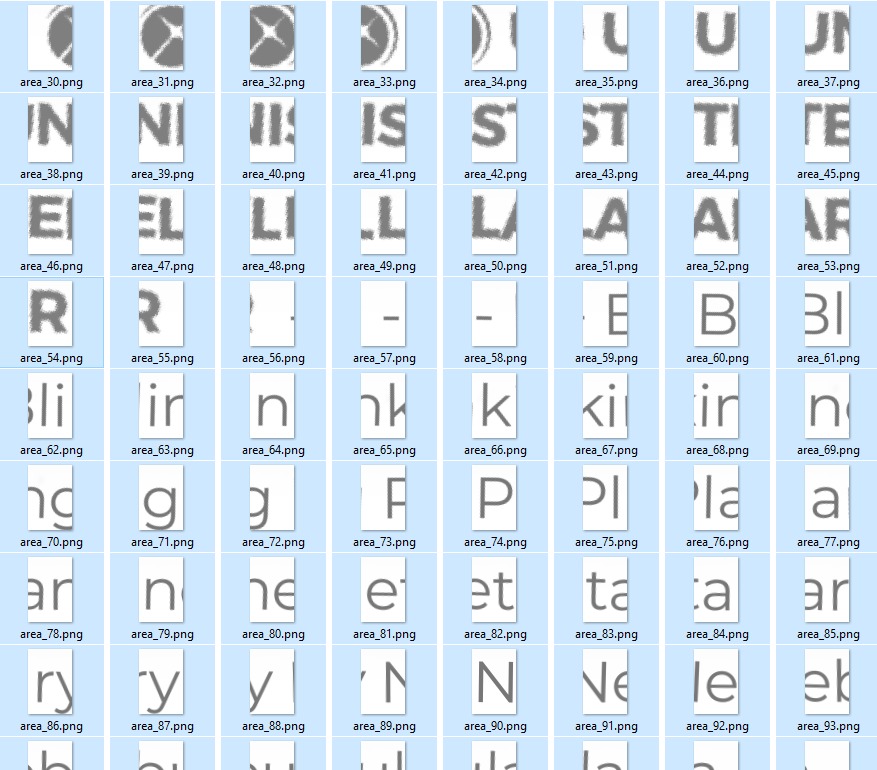
La fonction « AssembleImage » va devoir mettre cela correctement ensemble…
def AssembleImage(stacked_image,start,addimg,Debug=False):
#Assemble curved "EXIF" text image elements to prepare for OCR reading
#im must be large enough to store all added images
#both image but me "black and white" only
(thresh, addimg) = cv.threshold(addimg, 127, 255, cv.THRESH_BINARY)
#Start indicate next free position to add next image, shift : shifting value
shift=18
#first build a white empty array identical to im
image = np.zeros(stacked_image.shape,dtype=int) + 255
#next move addimg values to correct target position
for y in range(0,addimg.shape[0]):
for x in range(0,addimg.shape[1]):
image[y,start+x] = addimg[y,x]
#then add to original, average method on "black" added elements
stacked_image = np.where(image < 255, (stacked_image+image)/2, stacked_image)
return stacked_image, start+shift
Ce qui nous donne :
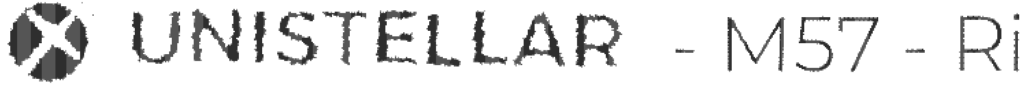
Ce qui est bien ce que l’on voulait ! Parfait, maintenant, il faut « interpréter » le contenu, un step « OCR » s’impose…
Optical Character Recognition (OCR)
Est la fonction qui transformera des « images de caractères » en « caractères », et nécessite un logiciel dédié pour cela… Ici, on va utiliser une fonction OCR basée sur Tesseract. Tesseract est un logiciel « open source » de text recognition (OCR), disponible sous Apache 2.0 license désormais supporté par Google. Ici, on va utiliser un « engine » local (sous Windows, dans mon cas) et un « wrapper » pour Python nommé pytesseract qui se chargera de l’appel des fonctions.
Pour que le programme en Python fonctionne, il faut donc deux choses :
– que pytesseract soit installé (via le pip install pytessract standard)
– que le module exécutable soit mis disponible sur le PC, soit en incluant la sub-dir d’installation dans le PATH, soit en précisant l’endroit lors de l’exécution :
# If you don't have tesseract executable in your PATH, include the following: pytesseract.pytesseract.tesseract_cmd = r'<full_path_to_your_tesseract_executable>'
# Example tesseract_cmd = r'C:\Program Files (x86)\Tesseract-OCR\tesseract'Pour ce qui est de l’exécutable, j’utilise un module assemblé pour Windows, (à installer comme une application normale) disponible ici.
Dans la version disponible, le « vocabulaire » reconnu est limité, mais suffit pour notre besoin (que les lettres majuscules, dans ce cas précis).
Ensuite, il suffit d’intégrer le tout…
On sauve l’image précédemment assemblée et on la passe à une fonction dédiée
def OCROnImage(filename,Debug=False):
#Tesseract call for OCR on "EXIF" like assembled elements
img = np.array(Image.open(filename))
text = pytesseract.image_to_string(img)
if Debug:
print("OCR Extracted text : ",text)
return textIl suffit ensuite d’intégrer le tout… Et quand le « nom » final peut être déterminé (selon le cas d’image), de renommer l’image originale dans la sub-dir « output/crop » générée avec le précédant utilitaire.
# -*- coding: utf-8 -*-
"""
Created on Fri Jul 6 11:30:25 2018
This program analyzes eVscope V1 / equinox 1 "crop" provided images :
- extract all capture information
- rename image files to incorporate info in filename
@author: TTFonWeb
"""
import glob
import skimage
import skimage.io
import skimage.feature
import skimage.color
import os
#import imageio
import datetime
import cv2 as cv
import numpy as np
import pytesseract
from PIL import Image
#from matplotlib import pyplot as plt
#from math import sqrt
#from skimage import data
#from skimage.color import rgb2gray
#Define functions
#****************************************
def CorrectObjectChar(text):
text = text.replace("/","-")
text = text.replace(" ","-")
text = text.replace(".","")
text = text.replace("I","1")
text = text.replace("S","5")
text = text.replace("O","0")
text = text.replace("Gh-","6h-")
text = text.replace("\n","")
return text
def CorrectTimeChar(text):
text = text.replace("/","-")
text = text.replace(" ","-")
text = text.replace(".","")
text = text.replace("I","1")
text = text.replace("S","5")
text = text.replace("O","0")
text = text.replace("\n","")
return text
def CorrectOCRChar(text):
text = text.replace("\n","")
text = text.replace("°","D")
text = text.replace("'","M")
text = text.replace("!","M")
text = text.replace('"','S')
text = text.replace(',','')
text = text.replace(".-",". -")
text = text.replace("-1","- 1")
text = text.replace("-0","- 0")
text = text.replace("-2","- 2")
text = text.replace("-3","- 3")
text = text.replace("-4","- 4")
text = text.replace("-5","- 5")
text = text.replace("-6","- 6")
text = text.replace("-7","- 7")
text = text.replace("-8","- 8")
text = text.replace("-9","- 9")
text = text.replace("-A","- A")
text = text.replace("-B","- B")
text = text.replace("-C","- C")
text = text.replace("-D","- D")
text = text.replace("-E","- E")
text = text.replace("-F","- F")
text = text.replace("-G","- G")
text = text.replace("-H","- H")
text = text.replace("-I","- I")
text = text.replace("-K","- K")
text = text.replace("-L","- L")
text = text.replace("-M","- M")
text = text.replace("-N","- N")
text = text.replace("-O","- O")
text = text.replace("-P","- P")
text = text.replace("-Q","- Q")
text = text.replace("-R","- R")
text = text.replace("-S","- S")
text = text.replace("-T","- T")
text = text.replace("-U","- U")
text = text.replace("-V","- V")
text = text.replace("-X","- X")
text = text.replace("-Y","- Y")
text = text.replace("-Z","- Z")
return text
def ExtractImage(path_out,mode, Debug=False):
cpt_convert=0
if mode not in ["crop", "cropbase"]:
print ("invalid image type : crop or cropbase" )
return False
listfiles=[]
for file in glob.glob(path_out + "\\"+mode+"\\"+mode+"*_orig.tif"):
listfiles.append(file)
if len(listfiles)>0:
print("Number of files : "+str(len(listfiles)))
log.write("> Number of 'crop' files : "+str(len(listfiles))+"\n")
log.write("> Observator files & extracted capture info\n")
for file in listfiles:
if os.name == "posix":
name = file.split('/')
else:
name = file.split('\\')
if len(name) > 0:
name = name[len(name)-1]
print("\nProcessing : "+name+"\n")
img_rgb = cv.imread(file)
if img_rgb.shape[2] == 4:
img_gray = cv.bitwise_not(cv.cvtColor(skimage.color.rgba2rgb(img_rgb), cv.COLOR_BGR2GRAY))
else:
img_gray = cv.bitwise_not(cv.cvtColor(img_rgb, cv.COLOR_BGR2GRAY))
(h, w) = img_gray.shape[:2]
(cX, cY) = (w // 2, h // 2)
# initial rotate our image by -90 degrees around the center of the image
M = cv.getRotationMatrix2D((cX, cY), 90, 1.0)
img_gray = cv.warpAffine(img_gray, M, (w, h))
#rotation allowed angle, 0 to 179 by 1
allowed_angle = np.arange(0, 180, 1, dtype=int)
angle=0
#will receive all image cropped elements
list_cutimages=[]
#sw to manage final image creation on cut shape size
defined=False
for angle in allowed_angle:
if angle > 0:
(h, w) = img_gray.shape[:2]
(cX, cY) = (w // 2, h // 2)
M = cv.getRotationMatrix2D((cX, cY), -angle, 1.0)
rotated = cv.warpAffine(img_gray, M, (w, h))
else:
rotated = img_gray
if mode == "crop":
cut_image = rotated[2127:2192, 1083:1127]
if mode == "cropbase":
cut_image = rotated[2127:2192, 1083:1127] #values to be determined, no image yet...
list_cutimages.append(cut_image)
if not defined:
final_image = np.zeros([cut_image.shape[0],cut_image.shape[1]*200],dtype=int) + 255
final_image, nextpos = AssembleImage(final_image,0,cut_image)
defined=True
else:
final_image, nextpos = AssembleImage(final_image,nextpos,cut_image)
ocrfilename=path_out + "\\" + mode + "\\ocr_"+ name.split(".")[0]+"_capture.png"
if Debug:
print("ocr file : ",ocrfilename)
cv.imwrite(ocrfilename,final_image)
#first step : convert image to char
text = OCROnImage(ocrfilename)
#second step : convert " - " sequence to split text objects
text = CorrectOCRChar(OCROnImage(ocrfilename))
#third step : build separate objects
elem = text.split(" - ")
#fourth step : rebuild separate elements with different logic
image_name = name.split(".")[0]
nbr_elem = len(elem)
if Debug:
print("image name : ", image_name)
print("text : ", text)
print("elem : ", elem)
print("nbr elem :",nbr_elem)
#target objects
objectname = ""
commonname = ""
duration = ""
localization = ""
date = ""
if nbr_elem == 6:
objectname = elem[1].strip()
commonname = elem[2].strip()
duration = elem[3].strip()
localization = elem[4].strip()
date = elem[5].strip()
if nbr_elem == 5:
objectname = "-"
commonname = elem[1].strip()
duration = elem[2].strip()
localization = elem[3].strip()
date = elem[4].strip()
if nbr_elem == 4:
objectname = "-"
commonname = elem[1].strip()
duration = elem[2].strip()
localization = elem[3].strip()
date = elem[4].strip()
objectname = CorrectObjectChar(objectname)
commonname = CorrectObjectChar(commonname)
duration = CorrectTimeChar(duration)
localization = CorrectObjectChar(localization)
date = CorrectTimeChar(date)
log.write("-"+name+" >"+image_name+" >"+objectname+" >"+commonname+" >"+duration+" >"+localization+" >"+date+"<\n")
capture_date = image_name.split("_")[1]
new_file_name = path_out+"\\"+mode+"\\crop_"+capture_date+"_iden"
if Debug:
print("New file name :",new_file_name)
new_file_name = new_file_name+"_"+objectname+"_"+commonname+"_"+duration+"_"+date+".tif"
if Debug:
print("New file name :",new_file_name)
try:
os.rename(file, new_file_name)
except:
print("error in rename : ",file,"\n by : ",new_file_name)
log.write("> error in rename : " +file+" by"+new_file_name+"<\n")
else:
print("rename : ",file,"\nby : ",new_file_name)
log.write("> rename : " +file+" by"+new_file_name+"<\n")
cpt_convert+=1
return cpt_convert
def AssembleImage(stacked_image,start,addimg,Debug=False):
#Assemble curved "EXIF" text image elements to prepare for OCR reading
#im must be large enough to store all added images
#both image but me "black and white" only
(thresh, addimg) = cv.threshold(addimg, 127, 255, cv.THRESH_BINARY)
#Start indicate next free position to add next image, shift : shifting value
shift=18
#first build an empty array identical to im
image = np.zeros(stacked_image.shape,dtype=int) + 255
#next move addimg values to correct target position
for y in range(0,addimg.shape[0]):
for x in range(0,addimg.shape[1]):
image[y,start+x] = addimg[y,x]
#then add to original, average method on "black" added elements
stacked_image = np.where(image < 255, (stacked_image+image)/2, stacked_image)
return stacked_image, start+shift
def OCROnImage(filename,Debug=False):
#Tesseract call for OCR on "EXIF" like assembled elements
img = np.array(Image.open(filename))
text = pytesseract.image_to_string(img)
if Debug:
print("OCR Extracted text : ",text)
return text
#Start of program
#****************************************
#running parameter
Debug=False
drive = "I:"
path = drive+"\\$Photo_Astro\\20220111-13_France"
path_in = path+"\\input"
path_out = path+"\\output"
#open log file
log=open(path+"\\TTFonWeb_eVscope_extractdata_runlog.txt","w")
now = datetime.datetime.now()
print ("> Current date and time : ",now.strftime("%Y-%m-%d %H:%M:%S"))
log.write("#TTFonWeb eVscope_extractdata V1.1, run : " + now.strftime("%Y-%m-%d %H:%M:%S")+"\n")
log.write(">Operator input sub_dir : "+ path_in +"\n")
log.write(">Observator input sub_dir : "+ path_out +"\n")
print("Extract information of observator images")
log.write("#"+"\n")
log.write("#Extract information of observator images"+"\n")
cpt = ExtractImage(path_out,"crop",Debug=True)
print("\nNumber of converted image : ",cpt)
#ExtractImage(path_out,"cropbase") Will be defined in future...
now = datetime.datetime.now()
print ("> Current date and time : ",now.strftime("%Y-%m-%d %H:%M:%S"))
log.write("#TTFonWeb eVscope_extractdata V1.1, end : " + now.strftime("%Y-%m-%d %H:%M:%S")+"\n")
log.close()Rem : les fonctions sont actuellement adaptée au format « crop », plus réaliste selon la procédure définie. La position dans les images « cropbase » n’est pas encore définie, à l’écriture de ces lignes… Je la mettrai à jour quand le cas se présentera.
Le programme complet devient simple :
# -*- coding: utf-8 -*-
"""
Created on Fri Jul 6 11:30:25 2018
This program analyzes eVscope "crop" provided images :
- extract all capture information
- rename image files to incorporate info in filename
@author: TTFonWeb
"""
import glob
import skimage
import skimage.io
import skimage.feature
import skimage.color
import os
import datetime
import cv2 as cv
import numpy as np
import pytesseract
from PIL import Image
#Define functions
#****************************************
def CorrectChar(text):
text = text.replace("/","-")
text = text.replace(" ","-")
text = text.replace(".","")
text = text.replace("I","1")
text = text.replace("S","5")
text = text.replace("O","0")
text = text.replace("\n","")
return text
def ExtractImage(path_out,mode, Debug=False):
cpt_convert=0
if mode not in ["crop", "cropbase"]:
print ("invalid image type : crop or cropbase" )
return False
listfiles=[]
for file in glob.glob(path_out + "\\"+mode+"\\"+mode+"*.tif"):
listfiles.append(file)
if len(listfiles)>0:
print("Number of files : "+str(len(listfiles)))
log.write("> Number of 'crop' files : "+str(len(listfiles))+"\n")
log.write("> Observator files & extracted capture info\n")
for file in listfiles:
if os.name == "posix":
name = file.split('/')
else:
name = file.split('\\')
if len(name) > 0:
name = name[len(name)-1]
print("Processing : "+name+"\n")
img_rgb = cv.imread(file)
if img_rgb.shape[2] == 4:
img_gray = cv.bitwise_not(cv.cvtColor(skimage.color.rgba2rgb(img_rgb), cv.COLOR_BGR2GRAY))
else:
img_gray = cv.bitwise_not(cv.cvtColor(img_rgb, cv.COLOR_BGR2GRAY))
(h, w) = img_gray.shape[:2]
(cX, cY) = (w // 2, h // 2)
# initial rotate our image by -90 degrees around the center of the image
M = cv.getRotationMatrix2D((cX, cY), 90, 1.0)
img_gray = cv.warpAffine(img_gray, M, (w, h))
#rotation allowed angle, 0 to 179 by 1
allowed_angle = np.arange(0, 180, 1, dtype=int)
angle=0
#will receive all image cropped elements
list_cutimages=[]
#sw to manage final image creation on cut shape size
defined=False
for angle in allowed_angle:
if angle > 0:
(h, w) = img_gray.shape[:2]
(cX, cY) = (w // 2, h // 2)
M = cv.getRotationMatrix2D((cX, cY), -angle, 1.0)
rotated = cv.warpAffine(img_gray, M, (w, h))
else:
rotated = img_gray
if mode == "crop":
cut_image = rotated[2127:2192, 1083:1127]
if mode == "cropbase":
cut_image = rotated[2127:2192, 1083:1127] #values to be determined, no image yet...
list_cutimages.append(cut_image)
if not defined:
final_image = np.zeros([cut_image.shape[0],cut_image.shape[1]*200],dtype=int) + 255
final_image, nextpos = AssembleImage(final_image,0,cut_image)
defined=True
else:
final_image, nextpos = AssembleImage(final_image,nextpos,cut_image)
ocrfilename=path_out + "\\" + mode + "\\ocr_"+ name.split(".")[0]+"_capture.png"
if Debug:
print("ocr file : ",ocrfilename)
cv.imwrite(ocrfilename,final_image)
text = OCROnImage(ocrfilename)
text = text.replace("\n","")
elem = text.split(" - ")
image_name = name.split(".")[0]
nbr_elem = len(elem)
print("image name : ", image_name)
print("text : ", text)
print("elem : ", elem)
print("nbr elem :",nbr_elem)
objectname = ""
commonname = ""
duration = ""
localization = ""
date = ""
if nbr_elem == 6:
objectname = elem[1].strip()
commonname = elem[2].strip()
duration = elem[3].strip()
localization = elem[4].strip()
date = elem[5].strip()
else:
objectname = elem[1].strip()
duration = elem[2].strip()
localization = elem[3].strip()
date = elem[4].strip()
objectname = CorrectChar(objectname)
commonname = CorrectChar(commonname)
duration = CorrectChar(duration)
localization = CorrectChar(localization)
date = CorrectChar(date)
log.write("-"+name+" >"+image_name+" >"+objectname+" >"+commonname+" >"+duration+" >"+localization+" >"+date+"<\n")
new_file_name = path_out+"\\"+mode+"\\"+image_name
if nbr_elem == 6:
new_file_name = new_file_name+"_"+objectname+"_"+commonname+"_"+duration+"_"+date+".tif"
else:
new_file_name = new_file_name+"_"+objectname+"_"+duration+"_"+date+".tif"
try:
os.rename(file, new_file_name)
except:
print("error in rename : ",file,"\n by : ",new_file_name)
log.write("> error in rename : " +file+" by"+new_file_name+"<\n")
else:
print("rename : ",file,"\nby : ",new_file_name)
log.write("> rename : " +file+" by"+new_file_name+"<\n")
cpt_convert+=1
return cpt_convert
def AssembleImage(stacked_image,start,addimg,Debug=False):
#Assemble curved "EXIF" text image elements to prepare for OCR reading
#im must be large enough to store all added images
#both image but me "black and white" only
(thresh, addimg) = cv.threshold(addimg, 127, 255, cv.THRESH_BINARY)
#Start indicate next free position to add next image, shift : shifting value
shift=18
#first build an empty array identical to im
image = np.zeros(stacked_image.shape,dtype=int) + 255
#next move addimg values to correct target position
for y in range(0,addimg.shape[0]):
for x in range(0,addimg.shape[1]):
image[y,start+x] = addimg[y,x]
#then add to original, average method on "black" added elements
stacked_image = np.where(image < 255, (stacked_image+image)/2, stacked_image)
return stacked_image, start+shift
def OCROnImage(filename,Debug=False):
#Tesseract call for OCR on "EXIF" like assembled elements
img = np.array(Image.open(filename))
text = pytesseract.image_to_string(img)
if Debug:
print("OCR Extracted text : ",text)
return text
#Start of program
#****************************************
#running parameter
Debug=False
drive = "I:"
path = drive+"\\$Photo_Astro\\20220105-EvscopeAtHome"
path_in = path+"\\input"
path_out = path+"\\output"
#open log file
log=open(path+"\\TTFonWeb_eVscope_extractdata_runlog.txt","w")
now = datetime.datetime.now()
print ("> Current date and time : ",now.strftime("%Y-%m-%d %H:%M:%S"))
log.write("#TTFonWeb eVscope_extractdata V1.1, run : " + now.strftime("%Y-%m-%d %H:%M:%S")+"\n")
log.write(">Operator input sub_dir : "+ path_in +"\n")
log.write(">Observator input sub_dir : "+ path_out +"\n")
print("Extract information of observator images")
log.write("#"+"\n")
log.write("#Extract information of observator images"+"\n")
cpt = ExtractImage(path_out,"crop",Debug=True)
print("\nNumber of converted image : ",cpt)
#ExtractImage(path_out,"cropbase") Will be defined in future...
log.close()
A l’exécution, on passe donc de :
crop_20220105-050431_orig.tif
crop_20220105-051044_orig.tif
crop_20220105-051910_orig.tif
crop_20220105-052157_orig.tif
crop_20220105-052209_orig.tif
crop_20220105-052923_orig.tif
crop_20220105-052933_orig.tif
crop_20220105-054401_orig.tif
crop_20220105-054536_orig.tif
crop_20220105-054544_orig.tif
crop_20220105-055112_orig.tif
crop_20220105-055329_orig.tif
crop_20220105-055425_orig.tif
crop_20220105-055524_orig.tif
crop_20220105-055533_orig.tifà
crop_20220105-055533_orig_Blinking-Planetary-Nebula_116sec_JANV-05-2022.tif
crop_20220105-050431_orig_M97_0wl-Nebula_14min_JANV-05-2022.tif
crop_20220105-051044_orig_M97_0wl-Nebula_20min_JANV-05-2022.tif
crop_20220105-051910_orig_67P-Churyumov-Gerasimenko_2min_JANV-05-2022.tif
crop_20220105-052157_orig_67P-Churyumov-Gerasimenko_5min_JANV-05-2022.tif
crop_20220105-052209_orig_67P-Churyumov-Gerasimenko_5min_JANV-05-2022.tif
crop_20220105-052923_orig_C-2018-X3-(PAN5TARR5)_84sec_JANV-05-2022.tif
crop_20220105-052933_orig_C-2018-X3-(PAN5TARR5)_88sec_JANV-05-2022.tif
crop_20220105-054401_orig_M57_Ring-Nebula_5min_JANV-05-2022.tif
crop_20220105-054536_orig_M57_Ring-Nebula_7min_JANV-05-2022.tif
crop_20220105-054544_orig_M57_Ring-Nebula_7min_JANV-05-2022.tif
crop_20220105-055112_orig_Blinking-Planetary-Nebula_36sec_JANV-05-2022.tif
crop_20220105-055329_orig_Blinking-Planetary-Nebula_76sec_JANV-05-2022.tif
crop_20220105-055425_orig_Blinking-Planetary-Nebula_52sec_JANV-05-2022.tif
crop_20220105-055524_orig_Blinking-Planetary-Nebula_112sec_JANV-05-2022.tifCe qui est tout de même plus « parlant »…
Adaptation pour l’Evscope / Equinox 2
L’arrivée du modèle de Evscope basé sur le IMX347 a modifié la taille des images…
Donc, voici une adaptation du programme ci-dessus qui traite indifféremment les images des deux types.
# -*- coding: utf-8 -*- « » » Created on Fri Jul 6 11:30:25 2018 This program analyzes eVscope « crop » provided images : – extract all capture information – support « mixed » elements stored at capture –
# -*- coding: utf-8 -*-
"""
Created on Fri Jul 6 11:30:25 2018
This program analyzes eVscope "crop" provided images :
- extract all capture information
- rename image files to incorporate info in filename
@author: TTFonWeb
"""
import glob
import skimage
import skimage.io
import skimage.feature
import skimage.color
import os
#import imageio
import datetime
import cv2 as cv
import numpy as np
import pytesseract
from PIL import Image
#from matplotlib import pyplot as plt
#from math import sqrt
#from skimage import data
#from skimage.color import rgb2gray
#Define functions
#****************************************
def ExtractCaptureElements(text):
#Common structure of capture elements varies largely
#
objectname = ""
commonname = ""
duration = ""
localization = ""
date = ""
objectname_sw = False
commonname_sw = False
duration_sw = False
localization_sw = False
date_sw = False
out=[]
for p in range(0,len(text)):
#organize on "-" separator
if text[p] =="-":
text = text.replace("/","-")
text = text.replace(" ","-")
text = text.replace(".","")
text = text.replace("I","1")
text = text.replace("S","5")
text = text.replace("O","0")
text = text.replace("\n","")
text = text.replace("\n","")
text = text.replace(".-",". -")
text = text.replace("-1","- 1")
text = text.replace("-0","- 0")
text = text.replace("-2","- 2")
text = text.replace("-3","- 3")
text = text.replace("-4","- 4")
text = text.replace("-5","- 5")
text = text.replace("-6","- 6")
text = text.replace("-7","- 7")
text = text.replace("-8","- 8")
text = text.replace("-9","- 9")
text = text.replace("-A","- A")
text = text.replace("-B","- B")
text = text.replace("-C","- C")
text = text.replace("-D","- D")
text = text.replace("-E","- E")
text = text.replace("-F","- F")
text = text.replace("-G","- G")
text = text.replace("-H","- H")
text = text.replace("-I","- I")
text = text.replace("-K","- K")
text = text.replace("-L","- L")
text = text.replace("-M","- M")
text = text.replace("-N","- N")
text = text.replace("-O","- O")
text = text.replace("-P","- P")
text = text.replace("-Q","- Q")
text = text.replace("-R","- R")
text = text.replace("-S","- S")
text = text.replace("-T","- T")
text = text.replace("-U","- U")
text = text.replace("-V","- V")
text = text.replace("-X","- X")
text = text.replace("-Y","- Y")
text = text.replace("-Z","- Z")
return text
def CorrectChar (text):
text = text.replace("/","-")
text = text.replace(" ","-")
text = text.replace(".","")
text = text.replace("I","1")
text = text.replace("S","5")
text = text.replace("O","0")
text = text.replace("\n","")
text = text.replace("\n","")
text = text.replace(".-",". -")
text = text.replace("-1","- 1")
text = text.replace("-0","- 0")
text = text.replace("-2","- 2")
text = text.replace("-3","- 3")
text = text.replace("-4","- 4")
text = text.replace("-5","- 5")
text = text.replace("-6","- 6")
text = text.replace("-7","- 7")
text = text.replace("-8","- 8")
text = text.replace("-9","- 9")
text = text.replace("-A","- A")
text = text.replace("-B","- B")
text = text.replace("-C","- C")
text = text.replace("-D","- D")
text = text.replace("-E","- E")
text = text.replace("-F","- F")
text = text.replace("-G","- G")
text = text.replace("-H","- H")
text = text.replace("-I","- I")
text = text.replace("-K","- K")
text = text.replace("-L","- L")
text = text.replace("-M","- M")
text = text.replace("-N","- N")
text = text.replace("-O","- O")
text = text.replace("-P","- P")
text = text.replace("-Q","- Q")
text = text.replace("-R","- R")
text = text.replace("-S","- S")
text = text.replace("-T","- T")
text = text.replace("-U","- U")
text = text.replace("-V","- V")
text = text.replace("-X","- X")
text = text.replace("-Y","- Y")
text = text.replace("-Z","- Z")
return text
def ExtractImage(path_in,path_out, Debug=False):
cpt_convert=0
listfiles=[]
for file in glob.glob(path_in + "\\evscope-*.png"):
listfiles.append(file)
if len(listfiles)>0:
print("Number of files : "+str(len(listfiles)))
log.write("> Number of files : "+str(len(listfiles))+"\n")
log.write("> Observator files & extracted capture info\n")
for file in listfiles:
if os.name == "posix":
name = file.split('/')
else:
name = file.split('\\')
if len(name) > 0:
name = name[len(name)-1]
print("\n****\nProcessing : "+name+"\n")
img_rgb = cv.imread(file)
h,w,c = img_rgb.shape
width = {2240:"crop1",2560:"full1",1280:"base1",1120:"cropbase1",
2520:"crop2",2880:"full2",2048:"base2",1792:"cropbase2",
0:"undefined"}
height = {2240:"crop1",1920:"full1",960:"base1",1120:"cropbase1",
2520:"crop2",2160:"full2",1536:"base2",1792:"cropbase2",
0:"undefined"}
imagetype=width[0]
for t in width:
if t == w :
imagetype=width[t]
print("Image type : ",imagetype+"\n")
if (imagetype == 'crop1') or (imagetype == 'crop2'):
if img_rgb.shape[2] == 4:
img_gray = cv.bitwise_not(cv.cvtColor(skimage.color.rgba2rgb(img_rgb), cv.COLOR_BGR2GRAY))
else:
img_gray = cv.bitwise_not(cv.cvtColor(img_rgb, cv.COLOR_BGR2GRAY))
(h, w) = img_gray.shape[:2]
(cX, cY) = (w // 2, h // 2)
# initial rotate our image by -90 degrees around the center of the image
M = cv.getRotationMatrix2D((cX, cY), 90, 1.0)
img_gray = cv.warpAffine(img_gray, M, (w, h))
#rotation allowed angle, 0 to 179 by 1
allowed_angle = np.arange(0, 180, 1, dtype=int)
angle=0
#will receive all image cropped elements
list_cutimages=[]
#sw to manage final image creation on cut shape size
defined=False
for angle in allowed_angle:
if angle > 0:
(h, w) = img_gray.shape[:2]
(cX, cY) = (w // 2, h // 2)
M = cv.getRotationMatrix2D((cX, cY), -angle, 1.0)
rotated = cv.warpAffine(img_gray, M, (w, h))
else:
rotated = img_gray
if imagetype == "crop1":
cut_image = rotated[2127:2192, 1083:1127]
if imagetype == "crop2":
cut_image = rotated[2388:2484, 1260:1320]
list_cutimages.append(cut_image)
if not defined:
final_image = np.zeros([cut_image.shape[0],cut_image.shape[1]*200],dtype=int) + 255
final_image, nextpos = AssembleImage(final_image,0,cut_image)
defined=True
else:
final_image, nextpos = AssembleImage(final_image,nextpos,cut_image)
ocrfilename=path_out + "\\ocr_"+ name.split(".")[0]+"_capture.png"
if Debug:
print("ocr file : ",ocrfilename+"\n")
cv.imwrite(ocrfilename,final_image)
text = OCROnImage(ocrfilename)
elem = text.split(" -")
image_name = name.split(".")[0]
nbr_elem = len(elem)
print("image name : ", image_name)
print("text : ", text)
print("elem : ", elem)
print("nbr elem :",nbr_elem)
objectname = ""
commonname = ""
duration = ""
localization = ""
date = ""
if nbr_elem == 6:
objectname = elem[1].strip()
commonname = elem[2].strip()
duration = elem[3].strip()
localization = elem[4].strip()
date = elem[5].strip()
if nbr_elem == 5:
objectname = "-"
commonname = elem[1].strip()
duration = elem[2].strip()
localization = elem[3].strip()
date = elem[4].strip()
if nbr_elem == 4:
objectname = "-"
commonname = elem[1].strip()
duration = elem[2].strip()
localization = elem[3].strip()
date = elem[3].strip()
objectname = CorrectChar(objectname)
commonname = CorrectChar(commonname)
duration = CorrectChar(duration)
localization = CorrectChar(localization)
date = CorrectChar(date)
log.write("-"+name+" >"+image_name+" >"+objectname+" >"+commonname+" >"+duration+" >"+localization+" >"+date+"<\n")
capture_date = image_name.split("-")[1]
new_file_name = path_out+"\\crop_"+capture_date+"_iden"
if Debug:
print("New file name :",new_file_name)
new_file_name = new_file_name+"_"+objectname+"_"+commonname+"_"+duration+"_"+date+".tif"
if Debug:
print("New file name :",new_file_name)
try:
os.rename(file, new_file_name)
except:
print("error in rename : ",file,"\n by : ",new_file_name)
log.write("> error in rename : " +file+" by"+new_file_name+"<\n")
else:
print("rename : ",file,"\nby : ",new_file_name)
log.write("> rename : " +file+" by"+new_file_name+"<\n")
cpt_convert+=1
return cpt_convert
def AssembleImage(stacked_image,start,addimg,Debug=False):
#Assemble curved "EXIF" text image elements to prepare for OCR reading
#im must be large enough to store all added images
#both image but me "black and white" only
(thresh, addimg) = cv.threshold(addimg, 127, 255, cv.THRESH_BINARY)
#Start indicate next free position to add next image, shift : shifting value
shift=18
#first build an empty array identical to im
image = np.zeros(stacked_image.shape,dtype=int) + 255
#next move addimg values to correct target position
for y in range(0,addimg.shape[0]):
for x in range(0,addimg.shape[1]):
image[y,start+x] = addimg[y,x]
#then add to original, average method on "black" added elements
stacked_image = np.where(image < 255, (stacked_image+image)/2, stacked_image)
return stacked_image, start+shift
def OCROnImage(filename,Debug=False):
#Tesseract call for OCR on "EXIF" like assembled elements
img = np.array(Image.open(filename))
text = pytesseract.image_to_string(img)
if Debug:
print("OCR Extracted text : ",text)
return text
#Start of program
#****************************************
#running parameter
Debug=False
drive = "I:"
path = drive+"\\$Evscope_work\\20230226_wezem_all"
path_in = path+"\\"
path_out = path+"\\"
#open log file
log=open(path+"\\TTFonWeb_eVscope_extractinfoa_runlog.txt","w")
now = datetime.datetime.now()
print ("> Current date and time : ",now.strftime("%Y-%m-%d %H:%M:%S"))
log.write("#TTFonWeb eVscope_extractinfo V1.0, run : " + now.strftime("%Y-%m-%d %H:%M:%S")+"\n")
log.write("> Input sub_dir : "+ path_in +"\n")
print("Extract information of observator images")
log.write("#"+"\n")
log.write("#Extract information of observator images"+"\n")
cpt = ExtractImage(path_in,path_out,Debug=True)
print("\nNumber of converted image : ",cpt)
#ExtractImage(path_out,"cropbase") Will be defined in future...
now = datetime.datetime.now()
print ("> Current date and time : ",now.strftime("%Y-%m-%d %H:%M:%S"))
log.write("#TTFonWeb eVscope_extractdata V1.1, end : " + now.strftime("%Y-%m-%d %H:%M:%S")+"\n")
log.close()
input("Press Enter to continue...")