
Comment gérer les mesures de pollution lumineuse ?
Depuis 2018, j’ai démarré l’observation continue de la pollution lumineuse du ciel à l’aide de différents capteurs. Depuis 2020, c’est un petit réseau de stations d’observation (nommée LPMD : Light Pollution Mobile Detector) qui s’est progressivement installé, avec la coopération de l’ASCEN et de Astronamur.
La mesure de la pollution lumineuse est une information clé pour estimer son impact sur notre biosphère, mais aussi pour confirmer ou infirmer des hypothèses courantes. D’autres mesures, combinant la photométrie à la spectrométrie, complète la vue.
Si prosaïquement, on veut pouvoir déterminer exactement l’influence d’un luminaire sur l’environnement, il y a d’autres aspects tout autant importants à observer, tel que :
- Influence de la période d’éclairage dans des zones sensibles
- Effets de l’extinction dans les différents types de site (effet compensatoire, ou pas, par la PL ambiante)
- Impact sur la durée « humaine » du cycle jour/nuit
- Etc…
Diverses études, le plus souvent en Asie, s’appuient sur des réseaux de capteurs identiques.
Pour connaître la théorie et comprendre le sujet, voici quelques sites :
http://www.ascen.be/ https://www.darksky.org/ https://fr.wikipedia.org/wiki/Pollution_lumineuse https://www.globeatnight.org/light-pollution.php
Le LPMD est une « station » indépendante connectée, basée sur divers composants :
- un Raspberry PI (mod. 3 et 4)
- une connexion internet (câblée ou wifi)
- Une distribution de l’OS Raspbian « customisée » pour l’astronomie (Easy Astro Box)
- Des programmes Python de contrôle
- Un ou plusieurs capteurs de Pollution Lumineuse
- Une camera (Type PI HD) avec objectif « All Sky »
- Un conteneur pouvant l’héberger pendant de longues durées sous la météo capricieuse de ma région.
Quel capteur et quel unité utiliser ?
Ces questions ont fait largement débat entre scientifiques pendant les séminaires internationaux sur le sujet, et les acteurs ne se sont finalement jamais mis vraiment d’accord. De nos jour, on utilise souvent la notion (physique) de irradiance en (W/m2, flux reçu par surface, proche du Lux en concept, mais pouvant englober toutes les longueurs d’onde).
Mais là aussi, il faut distinguer son usage en astronomie et astrophysique, avec des notions comme « Intensité » et « Irradiance spectrale »(sur une longueur d’onde). Ces concepts sont appréciés par les astrophysiciens mais exigent des capteurs adaptés (et calibrés) difficiles à trouver ou fabriquer pour l’amateur.
Si les mesures via satellites (généralement payantes) s’avèrent la meilleure solution pour obtenir une vue générale du sujet sur une région, les mesures au sol sont indispensables pour étudier les aspects sur la faune locale.
En terme de capteur depuis le sol, plusieurs capteurs « low-cost » ont bien été réalisés par divers acteurs, que le IYA Lightmeter (qui fut d’ailleurs utilisé dans les versions précédentes du LPMD)
Cette mesure peut s’effectuer au niveau amateur depuis le sol via trois outils :
- Un « luminomètre », un appareil généralement assez couteux pour disposer d’une mesure suffisamment sensible.
- Un sky quality meter (SQM) (ou instrument de mesure de la qualité du ciel sur des longueurs d’ondes « visibles ». Accessible financièrement, il existe diverses versions, des « compatibles » et même des « DIY »
- Des photos du ciel… A partir du moment où on a calibré son APN pour le faire.
Pour une solution « low cost », je vais donc en revenir à une notion plus abstraite, mais largement utilisée par les amateurs du monde entier : la magnitude surfacique (mag/arcsec²) ou MPSAS (Magnitude Per Square ArcSec), qui est connue par 100% de ceux-ci.
Le principe est simple : au plus cette valeur est élevée, au plus le ciel est noir. On peut aussi exprimer cette valeur via le NELM (Naked Eyes Limiting Magnitude) qui fournit une idée de ce qui est qui est visible à l’œil nu (mais comme la sensibilité de chaque oeil varie par individu, c’est forcément plus indicatif qu’autre chose).
Comme c’est une « magnitude » : un écart de +1 magnitude signifie 2.5 fois moins de lumière provenant de la zone observée. Un écart de 5 mag/arcsec² indique une différence de 100x plus sombre ou plus clair.
On l’interprète couramment cette valeur selon :
- > 22 : meilleur ciel théorique sur Terre (avec son atmosphère, allez au Pole Sud pour le rencontrer…)
- 22.0 : une nuit sans Lune sans aucun lumière artificielle (là où on construit les observatoires…)
- 21.0 : typique d’un ciel rural sans pollution lumineuse (toutes les constellations, voie lactée sont visibles)
- 20.0 : typique d’une zone périurbaine où la visibilité de la Voie lactée est déjà fortement atteinte
- 19.0 : typique d’une zone périurbaine avec des maisons proches l’une des autres (la majorité des constellations sont reconnaissables)
- 18.0 : typique pour une zone périurbaine déjà fort éclairée (une partie des constellations est reconnaissable)
- 17.0 : la vue du ciel depuis une ville éclairée (quelques étoiles sont visibles à l’oeil nu)
- 13.0 : limite de la « nuit », le Soleil s’est civilement couché (-6° sous l’horizon), Venus and Jupiter sont visibles, les étoiles les plus brillantes (mag 0) apparaissent.
- 7.0 : le Soleil se lève civilement
- < 7.0 : Lumière du jour
Dans les modèles considérés, quelques limites définies :
- mesure >= 13 MPSAS = ‘période de nuit’ (Night Period)
- mesure >= 19 MPSAS = ‘période de nuit profonde’ (Dark Period)
- On considère que dépassé 19 MPSAS, la nuit commence à être valable au niveau de la conservation de la biosphère (végétaux, animaux, humanité)
Pour mesurer tout ceci, j’utilise un capteur fort documenté et connu : le Unihedron SQM/LU, reconnu pour sa fiabilité et stabilité.
Mon plus ancien capteur a tenu bon 6 ans dans des situations extrêmes (de +60 à -25°)
Les stations installées
Ces trois détecteurs vu leur distribution géographique (Provinces : Brabant Flamand, Namur, Luxembourg), l’influence de la pollution lumineuse typique en Belgique, en s’éloignant de la zone Bruxelloise vers la Frontière française.
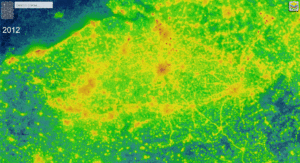 Evolution de la PL jusque 2019 (vue satellite, site https://lighttrends.lightpollutionmap.info)
Evolution de la PL jusque 2019 (vue satellite, site https://lighttrends.lightpollutionmap.info)
La construction d’un LPMD est un processus évolutif que je ne décrirai pas ici (si on est intéressé, adressez-vous à l’ASCEN, qui transmettra).
On est actuellement à la version 6 (basée API) et la version 7 (basée une technologie IOT) est en cours d’élaboration.
Ici, voyons ici des programmes qui peuvent intéresser ceux voulant d’effectuer captures et statistiques de leur côté.
Traitement des données cumulatives issues d’un SQM/LU/DL Unihedron
Mon premier capteur (SQM/DL/LU) est un « enregistreur » de données automatique et parfaitement indépendant (6 piles = plusieurs mois de données, selon la fréquence). Mais quand on récupère les données de temps en temps, cela peut mener à disposer de plusieurs fichiers cumulatifs couvrant des périodes identiques.
On doit donc trier, supprimer les doubles et obtenir des données de tendances.
Je vous propose ici deux manières de réaliser cela via programmation : du « pur » Python et Python + Pandas
Le fichier « .dat » fournit par le logiciel contient des lignes utiles pour gérer les informations de localisation (préfixées par « # »), mais qui ne seront pas utiles ensuite. Je les supprime automatiquement au sauvetage dans la bonne directory de stockage par localisation/date.
Ensuite, les données utiles sont stockées en philosophie « comma separated » (mais avec « ; »).
Un exemple :
2018-04-08T18:30:10.000;2018-04-08T20:30:10.000;18.0;4.91;9.68
=> UTC; LT; Temp(°C); Volt; Mag (en mag/arcsec²) Pur Python : Lire, ordonner, calibrer, supprimer les données inutiles (<=10 mag/arcsec²), enlever les doubles, sauver…
# -*- coding: utf-8 -*-
"""
Created on Sun May 27 09:25:40 2018
@author: TTF
First mandatory step : all SQM csv files are concatenated into a single one,
by a simple "type *.dat > SQM_Global.csv" command and previously "cleaned" for useless lines at capture time
"""
import os, sys,shutil
import time
#start operation
start=time.time()
#First, sort file
with open("F:\\data\\Logs_SQM\\SQM_Global.csv","r") as f:
sorted_file = sorted(f)
with open("F:\\data\\Logs_SQM\\SQM_Global_Sort.csv","w") as f:
f.writelines(sorted_file)
#Now examine each lines
SQMin = open("F:\\data\\Logs_SQM\\SQM_Global_Sort.csv", "r",encoding="utf-8")
SQMout = open("F:\\data\\Logs_SQM\\PI_SQM_Global.csv", "w",encoding="utf-8")
Previous = ""
Current = SQMin.readline() # read a first record
Calib = 0.11
Count_Lu = 0
Count_Double = 0
Count_Valid = 0
Count_Invalid = 0
Magval = 0.0
while Current != "": # end of file
Count_Lu = Count_Lu + 1
if Current != Previous :
UTC, LC, Temp, Volt, Mag = Current.split(';')
Magval = float(Mag)
if (Magval + Calib) >= 10:
rec_out = LC + "," + Temp + "," + Volt + "," + str(Magval + Calib) + "\n"
SQMout.write(rec_out)
Count_Valid = Count_Valid + 1
else:
Count_Invalid = Count_Invalid + 1
Previous = Current
Current = SQMin.readline()
else:
Count_Double = Count_Double + 1
Current = SQMin.readline()
SQMin.close()
SQMout.close()
print("Nombre mesures lues : "+str(Count_Lu))
print("Nombre mesures en double : "+str(Count_Double))
print("Nombre mesures invalides : "+str(Count_Invalid))
print("Nombre mesures Valides : "+str(Count_Valid))
end=time.time()
print("Start Time : "+str(start))
print("End Time : "+str(end))
print("Duration : "+str(end-start)+" sec")=> Pour trier et traiter 21625 lignes = 0,05 sec…
Python + Pandas : processus identique…
# -*- coding: utf-8 -*-
"""
Created on Sat May 26 07:29:05 2018
@author: TTF
First mandatory step : all SQM csv files are concatenated into a single one,
by a simple "type *.dat > SQM_Global.csv" command and previously "cleaned" for useless lines at capture time
"""
from pandas import *
import time
#start operation
start=time.time()
#read all data
sqm_df = read_csv("F:\\data\\Logs_SQM\\SQM_Global.csv",
delimiter=';',
names=['UTC','LC','Temp','Volt','Mag'],
parse_dates={'datetime': ['LC']})
#sort by date and time
df = sqm_df.sort_values(by='datetime')
#add calibration
sqm_df['Calib'] = 0.11
sqm_df['Mag'] = sqm_df['Mag'] + sqm_df['Calib']
sqmtoclean_df = sqm_df.drop(columns='Calib')
#suppress duplicate records
sqmclean_df = sqmtoclean_df.drop_duplicates(keep='first')
#suppress useless records
sqmdata_df = sqmclean_df[sqmclean_df["Mag"] >= 10]
#save epured data
sqmout = sqmdata_df.loc[:,['datetime','Temp','Volt','Mag']]
sqmout.to_csv("F:\\data\\Logs_SQM\\Pandas_SQM_Global.csv",
index=False)
end=time.time()
print("Start Time : "+str(start))
print("End Time : "+str(end))
print("Duration : "+str(end-start)+" sec")Quelques remarques :
- La calibration : dans les deux cas, on « ajoute » 0.11 mag/arcsec² à chaque mesure, une différence due à la transparence du plastique qui protège le capteur dans sa protection « all weather » (à déterminer selon le cas…)
- La syntaxe et possibilités…
- Le but n’est pas de faire un cours de Pandas, mais cette librairie est dédiée « Data analysis » et offre des capacités d’analyse statistique étendues (Corrélation, déviation, covariance, Kurtosis, Asymétrie, etc…) en quelques commandes.
Par exemple :
from pandas import *
#read all data
sqm_df = read_csv("F:\\data\\Logs_SQM\\Pandas_SQM_Global.csv")
plt.figure(); sqm_df.plot()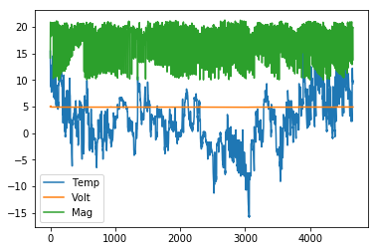
Ou on découvre qu’il a fait jusque -15°C … 🙂 Et si c’est le cas, il y a-t-il une relation entre température et qualité du ciel ?
Q : s’il fait froid, le ciel est-t-il plus dégagé, donc plus noir ?
from pandas import *
#read all data
sqm_df = read_csv("F:\\data\\Logs_SQM\\Pandas_SQM_Global.csv")
#only keep SQM over 17 Mag/arcsec²
sqmdata_df = sqm_df[sqm_df["Mag"] >= 17]
#analyse data by plotting them
sqmdata_df.plot(kind="scatter",x="Temp", y="Mag")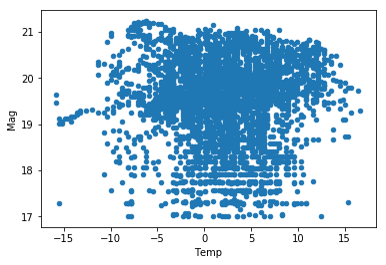
R : Apparemment, de 0 à -8°, c’est vrai.. Mais a une température plus basse (<10°) correspond une magnitude proche de 19, ce qui serait plutôt l’inverse…!
Exemple 2 : « Automatic archive » de données SQM
Tout le monde n’a pas un serveur avec une DB sous la main… Et d’ailleurs, quand on veut garder des données longtemps, autant avoir des copies « fichiers » quelque part…
Mais d’un autre côté, quand on revient d’une prise de mesure, ou on met à jour (trop) rapidement ses données avec la capture du jour (entre deux autres activités) : « shit can happen » 🙂 Et c’est à ce moment-là que l’on s’aperçoit que l’on a mélange/effacé/mal stocké LE fichier que vous avez justement besoin maintenant ! (Murphy’s Law application)
Mesure : les SQM de Unihedron peuvent être à lecture immédiate (/LE/LU) ou différée (/DL). Dans ce dernier cas, le boitier fonctionne seul sur batterie, les mesures sont prises à une période fixe (ex : 30 min) et les données sont stockées, à localement (jusque 32K mesures, donc à 30 Min/mesure = 2 ans de données !). Si on efface la mémoire locale, mieux vaut ne pas perdre ses fichiers ! Mais.. La connexion pour les récupérer est lente (« série » sur USB) et si on laisse les mesures dans la mémoire, elles se cumulent à chaque sauvetage => exploitation immédiate difficile.
Donc, le programme suivant vise à minimiser les erreurs humaines…
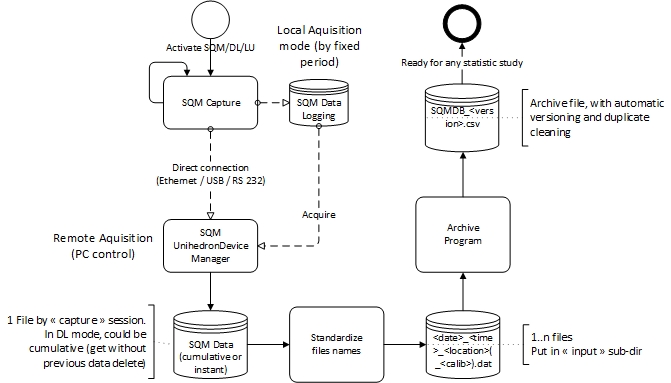
Son but est d’archiver automatiquement les fichiers de données (sans trop faire attention au contenu cumulé ou pas), avec des « versions » de l’archive (en cas de problèmes : on peut repartir avec la version précédente).
Seule obligation : standardiser les fichiers de capture selon le format suivant : <date>_<heure>_<location>(_<calibration>).dat <date> : format yyyymmdd <heure> : format hhmmss <location> : une chaîne de caractères libre, mais sans blanc, pour indiquer l’endroit de la mesure <calibration> : optionnel, à fournir si la valeur de calibration par défaut (normalement mise dans le programme) doit être remplacée par celle-ci. « .dat » : pour indiquer un fichier de type SQM data Remarque : les caractères « _ » sont importants…
A l’entrée : tous les fichiers de mesures (type .dat), avec le nom standardisés, sont mis dans une sub-dir fixée (définition dans le programme) A la sortie : une sub-dir fixée contiendra les « archives » des données. Ce fichier avec nom standard : SQM_DB_<numéro de version> (en 4 positions, 0000 au départ).csv. A chaque exécution :
- Le dernier fichier « archive » présent est détecté et nouvelle version sera créée (0000 => 0001 => 0002, etc…)
- le contenu de tous les fichiers détectés à l’entrée seront ajoutés au fichier « archive » courant, avec calibration et le nom de la localisation ajoutée à chaque mesure. En finale : tous les doubles éventuels sont supprimés.
Ce fichier « archive « pourra facilement être chargé dans une DB ou un programme (ex : python dataframe (Pandas)) pour des études.
# -*- coding: utf-8 -*-
"""
Created on Sat May 26 07:29:05 2018
@author: TTF
Target : add a SQM report to a global archive file for Pandas processing
"""
import pandas as pd
import glob
#initialise path & repository values, if "*" = automatic version
repositoryInputVersion = '*'
repositoryOutputVersion = '*'
repositoryPath = 'E:\\SQM\\$SQM_Repository\\'
inputPattern = 'E:\\SQM\\Input\\*.dat'
#check for dynamic or static allocation for input repository
if (repositoryInputVersion == '*'):
repositoryInputFile=""
for fname in glob.glob(repositoryPath+"SQM_DB_*", recursive=True):
if fname > repositoryInputFile:
repositoryInputFile = fname
print("Last archive selected :",repositoryInputFile)
else:
repositoryInputFile = repositoryPath+'SQM_DB_'+ repositoryInputVersion +'.csv'
#check for dynamic or static allocation for output repository
if (repositoryOutputVersion == '*'):
elem = repositoryInputFile.split("\\")
lastvalue=elem[len(elem)-1].split(".")[0]
elem = lastvalue.split("_")
repositoryOutputVersion=str(int(elem[len(elem)-1]) + 1).zfill(4)
print("New archive version selected :",repositoryOutputVersion)
repositoryOutputFile = repositoryPath + "SQM_DB_" + repositoryOutputVersion +'.csv'
#open repositoryfile
sqm_DB = pd.read_csv(repositoryInputFile,delimiter=';',comment='#',
names=['Location','UTC','LC','Temp','Volt','Mag'])
print("Previous archive read :",sqm_DB.size,"records")
cpt_fname=0
#scan for new file
#Standard filename is <Date>"_"<time>"_"<location>("_"<calibration>)".dat"
for fname in glob.glob(inputPattern, recursive=True):
print("Input selected :",fname)
cpt_fname+=1
#default calibration_value for plastic transparency (100x real value)
calibration= 0.11
calib_value= "0"
#if present in filename, override default calibration
try:
path, date, time, location, calib_value = fname.split("_")
calib_value = calib_value.split('.')[0]
except ValueError:
path, date, time, location = fname.split("_")
location=location.split('.')[0]
print("Current location : ",location)
#calibration put in filename is 100x value and must be valid
if (float(calib_value) > 0):
calibration = float(calib_value) / 100
#read new SQM data file
df_read = pd.read_csv(fname,delimiter=';',comment='#',
names=['UTC','LC','Temp','Volt','Mag'])
#add data to frame & add calibration on all magnitude
df_read['Location']=location
df_read['Calib'] = calibration
df_read['Mag'] = df_read['Mag'] + df_read['Calib']
clean_df = df_read.drop(columns='Calib')
#sort by UTC
df = clean_df.sort_values(by='UTC')
#add to repository
frames = [sqm_DB,df]
sqm_DB = pd.concat(frames)
print("Add ",df_read.size," records to existing",sqm_DB.size)
print("*** End add of", cpt_fname," data files added")
#suppress any duplicate (location, time, value)
print("Before clean : ",sqm_DB.size,"records")
sqm_DB = sqm_DB.drop_duplicates(keep='first')
print("After clean : ",sqm_DB.size,"records saved")
#save new repository
sqmout = sqm_DB.loc[:,['Location','UTC','LC','Temp','Volt','Mag']]
sqmout.to_csv(repositoryOutputFile,index=False,sep=';')
print(repositoryOutputFile,"archive saved")A l’exécution (en considérant 3 fichiers présents à l’entrée)
Last repository selected : E:\\SQM\$SQM_Repository\SQM_DB_0000.csv
New repository value selected : 0001
Initial repository read : 0 records
Input selected : E:\SQM\Input\20180224_173752_LOC1.dat
Current location : LOC1
Add 34181 records to existing 29298
Input selected : E:\SQM\Input\20180408_194947_LOC1.dat
Current location : LOC1
Add 47495 records to existing 70008
Input selected : E:\SQM\Input\20200420_104312_LOC2_30.dat
Current location : LOC2
Add 61712 records to existing 122904
*** End add of 3 data files added
Before clean : 122904 records
After clean : 93606 records saved
E:\SQM\$SQM_Repository\SQM_DB_0001.csv repository savedRemarque : on peut fixer le nom précis d’une version d’une archive (enlever les « * »), sinon tout est automatique par défaut…
Si on regarde le contenu, au niveau Python… La variable « sqmOut » est un dataframe, c’est-à-dire :
C’est une structure de table extrêmement puissante pour la librairie Pandas, qui permettra de faire des travaux de statistiques de manière simplifiée. Ainsi, une vue synthétique des données stockées s’obtient via :
sqmout.describe()
Out[3]:
Location UTC ... Volt Mag
count 31203 31203 ... 31203 31203
unique 3 15602 ... 47 3015
top LOC2 2018-03-19T23:00:08.000 ... 4.88 0.3
freq 17632 2 ... 4885 4963
[4 rows x 6 columns]